A continuación vamos a bordar el análisis de un modelo de regresión lineal uniecuacional multiple pasando por la estimación del modelo, la comprobación de las hipótesis básicas del mismo y su corrección.
Para ello trabajaremos con los datos macroeconómicos de Longley (disponibles en R) ampliamente usados como ejemplo de regresión con alta colinealidad.
head(longley) # vemos el nombre de cada una de las variables y primeros datos
Call:
lm(formula = Employed ~ GNP.deflator + GNP + Population)
Residuals:
Min 1Q Median 3Q Max
-0.75233 -0.34965 -0.01369 0.29628 0.97765
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 102.03085 15.77995 6.466 3.09e-05 ***
GNP.deflator -0.14815 0.09851 -1.504 0.158476
GNP 0.08235 0.01631 5.050 0.000285 ***
Population -0.45626 0.14851 -3.072 0.009676 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5212 on 12 degrees of freedom
Multiple R-squared: 0.9824, Adjusted R-squared: 0.978
F-statistic: 223 on 3 and 12 DF, p-value: 8.711e-11
Se puede observar que los resultados obtenidos se adaptan plenamente a los contenidos estudiados en cualquier curso de Econometría básica. Así, se obtiene:
Una información básica sobre los residuos del modelo que tienen por objetivo intuir si éstos son simétricos (mediana próxima a cero y cuartiles y mínimos/máximos con valores opuestos).
Estimación de los coeficientes de las variables independientes junto a su desviación típica estimada.
El valor experimental de los contrastes de significación individual (cociente de las dos columnas anteriores), así como el p-valor asociado a estos contrastes.
Raíz cuadrada de la varianza de la perturbación aleatoria.
Coeficiente de determinación y el corregido.
Valor experimental y p-valor asociado al contraste de significación conjunta.
Algunas cantidades interesantes pueden ser:
regresion$coefficients # coeficientes estimados
(Intercept) GNP.deflator GNP Population
102.03084850 -0.14815069 0.08234892 -0.45626319
confint(regresion) # intervalos de confianza de los coeficientes de los regresores
AIC(regresion) # criterio de información de Akaike
[1] 29.95213
BIC(regresion) # criterio de información de Scharwz
[1] 33.81508
Para más detalle escribir help(lm) en la consola.
(In)cumplimiento de las hipótesis básicas del modelo
Multicolinealidad
Detección mediante el determinante de la matriz de correlaciones (valores próximos a cero indican relación lineal alta y valores próximos a uno relación lineal baja):
X =cbind(GNP.deflator,GNP,Population) # matriz de variables independientesdet(cor(X))
[1] 0.0002842754
Mediante el Factor de Inflación de la Varianza (valores superiores a 10 indican multicolinealidad preocupante):
source("funciones.txt") # cargo un .txt que contiene funciones para calcular el FIV y NCFIV(X)
[1] 62.40594 145.06696 58.92490
Mediante el Número de Condición (valores superiores a 30 indican multicolinealidad preocupante):
NC(X)
[1] 324.1011
cte =array(1,length(Employed))NC(cbind(cte,X))
[1] 51843.74
Todos los resultados obtenidos indican que en el modelo hay un problema de multicolinealidad preocupante. Además, el cálculo del NC con y sin constante indica que existe una alta relación lineal con la constante.
Aunque el modelo analizado es una serie temporal y la heterocedasticidad surge en datos de sección cruzada, a continuación veremos a modo ilustrativo cómo detectaríamos si existe este problema.
Detección mediante métodos gráficos
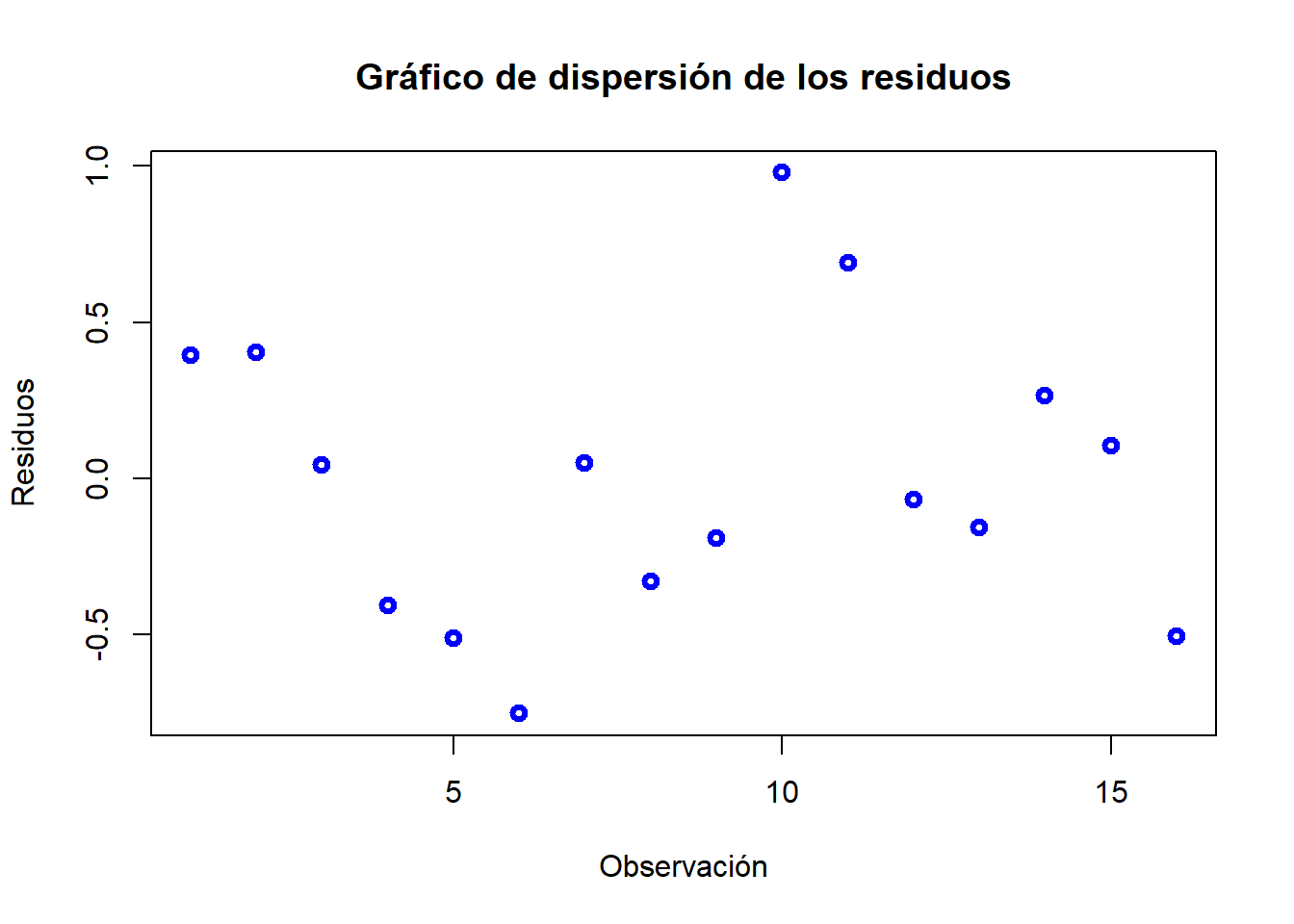
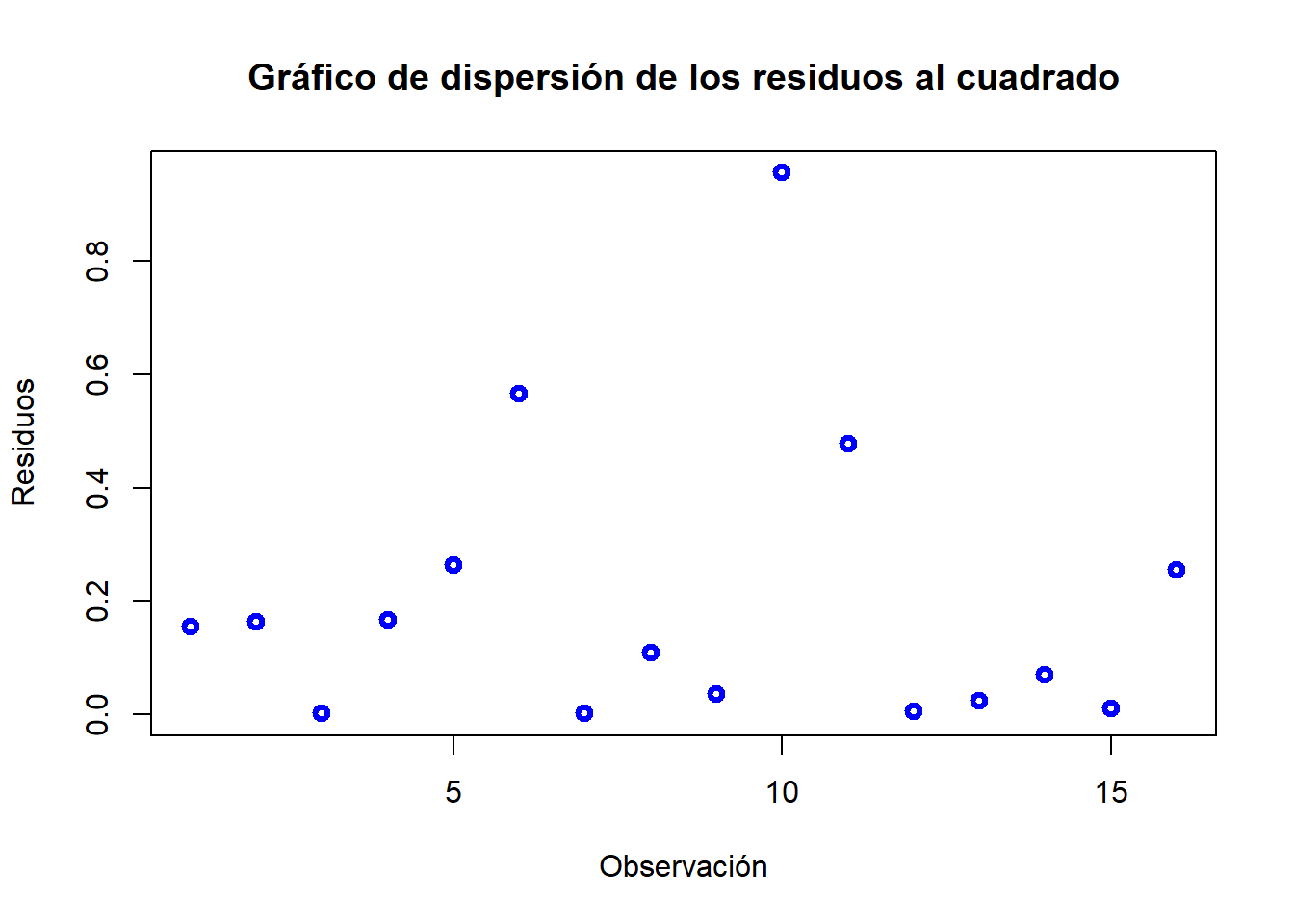
Mediante los gráficos de dispersión de los residuos o residuos al cuadrado:
e = regresion$residuals plot(e, ylab="Residuos", xlab="Observación", col="blue", lwd=3, main="Gráfico de dispersión de los residuos")
e.2= e^2plot(e.2, ylab="Residuos", xlab="Observación", col="blue", lwd=3, main="Gráfico de dispersión de los residuos al cuadrado")
Buscamos grupos de observaciones con distinta varianza. Parece no observarse nada.
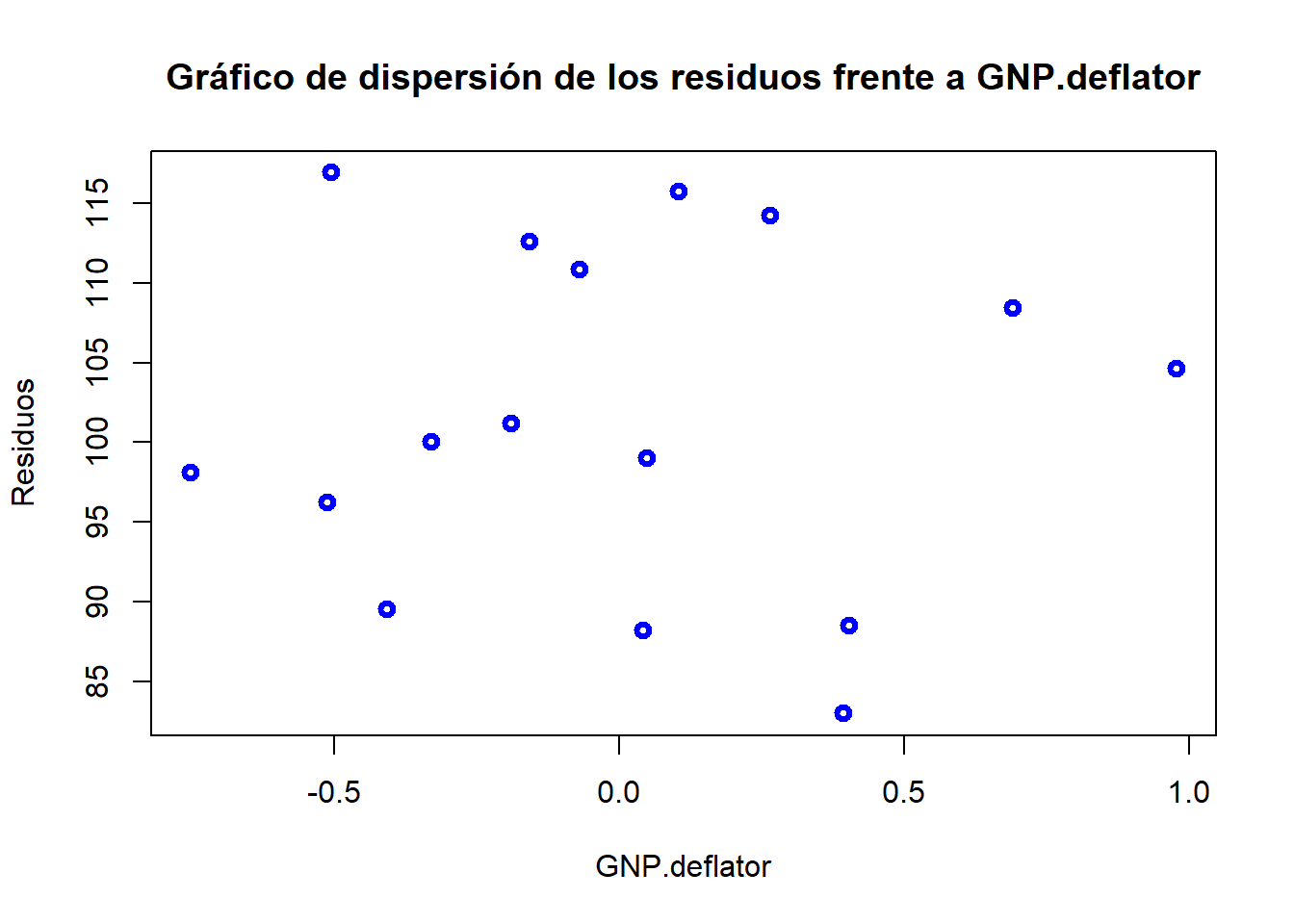
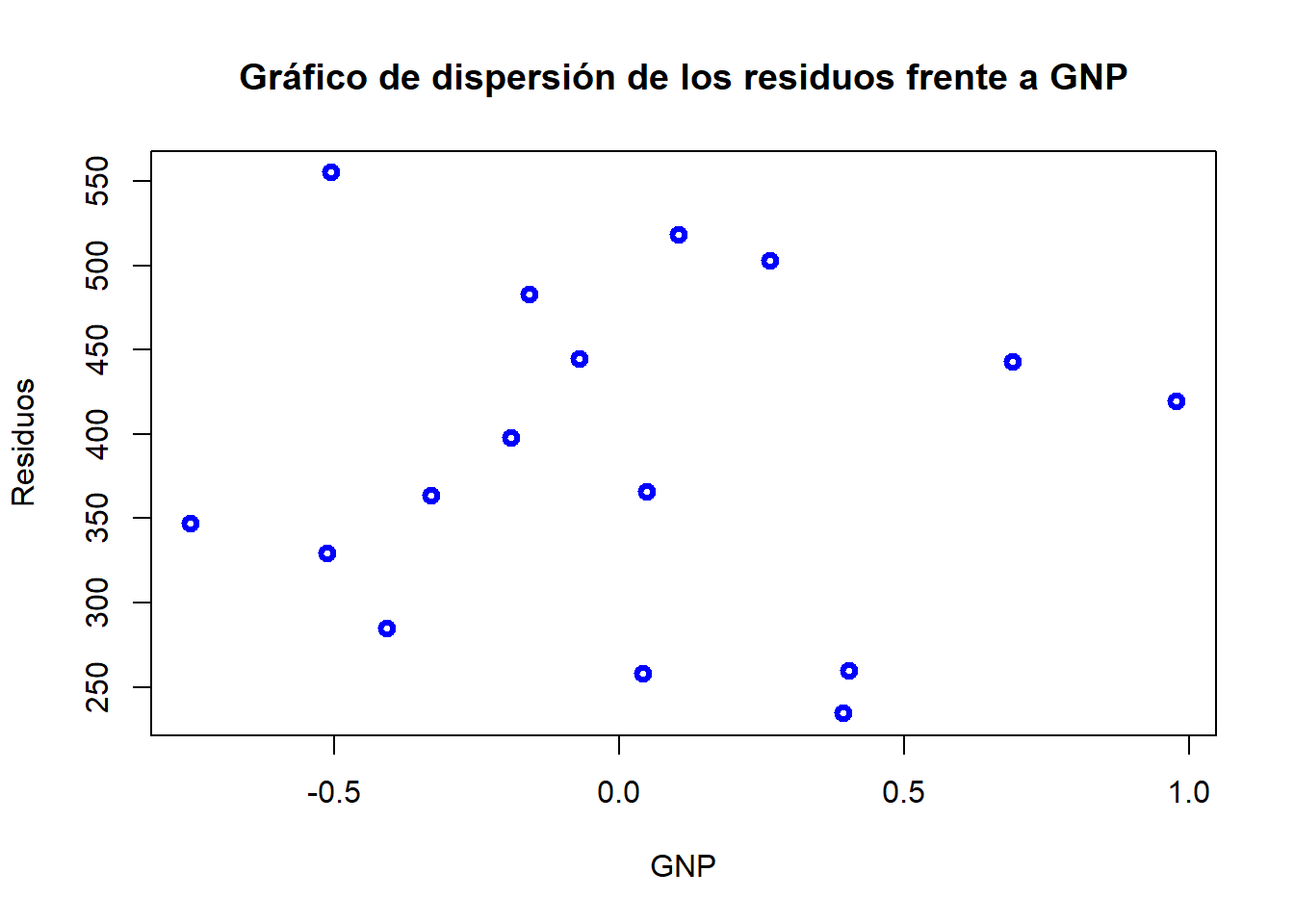
Mediante los gráficos de dispersión de los residuos o residuos al cuadrado frente a la variable independiente que se sospecha provoca el problema:
plot(e, GNP.deflator, ylab="Residuos", xlab="GNP.deflator", col="blue", lwd=3, main="Gráfico de dispersión de los residuos frente a GNP.deflator")
plot(e, GNP, ylab="Residuos", xlab="GNP", col="blue", lwd=3, main="Gráfico de dispersión de los residuos frente a GNP")
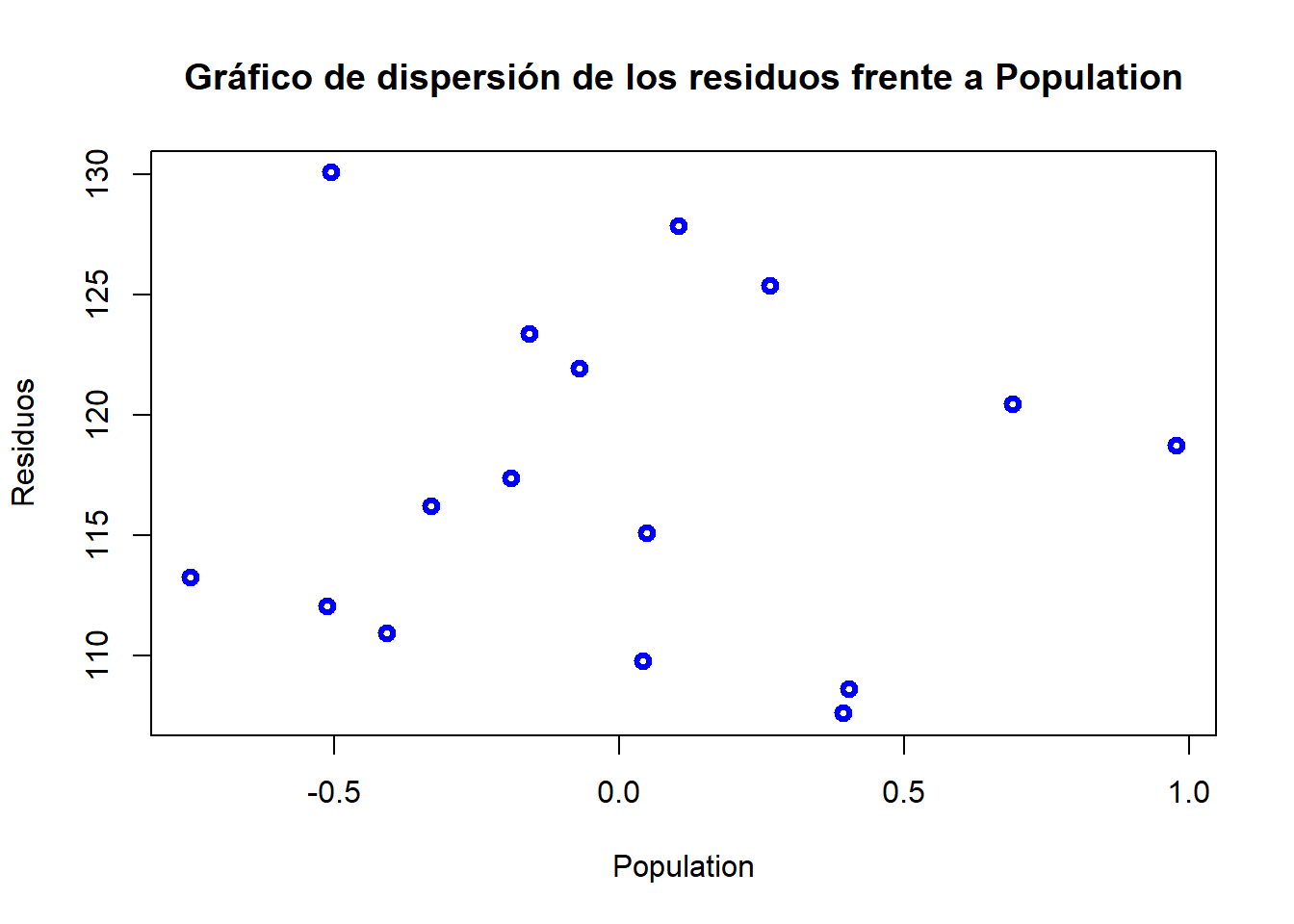
plot(e, Population, ylab="Residuos", xlab="Population", col="blue", lwd=3, main="Gráfico de dispersión de los residuos frente a Population")
En este segundo caso se busca si la variabilidad de los residuos aumenta o disminuye conforme aumenta la variable independiente. Igualmente parece no observarse nada.
if (valor.experimental > valor.teorico){print("Rechazo la hipótesis nula de homocedasticidad")} else {print("No rechazo la hipótesis nula de homocedasticidad")}
[1] "No rechazo la hipótesis nula de homocedasticidad"
if (valor.experimental > valor.teorico){print("Rechazo la hipótesis nula de homocedasticidad")} else {print("No rechazo la hipótesis nula de homocedasticidad")}
[1] "No rechazo la hipótesis nula de homocedasticidad"
Puesto que los métodos gráficos no nos hacen sospechar de la existencia de un problema de heterocedasticidad, menos aún nos indican qué variable es la responsable. En cualquier caso usaremos la variable GNP para ilustrar cómo se implementaría el test de Glesjer:
var = GNP # sólo hay que cambiar aquí la variable independiente a usarvalores.h =c(-2, -1, -0.5, 0.5, 1, 2)p.valor =array(,length(valores.h))R2 =array(,length(valores.h))i =1homocedasticidad =1for (h in valores.h){ var.aux = var^h reg.aux =lm(e.2~var.aux) p.valor[i] =summary(reg.aux)[[4]][2,4]if (p.valor[i] <0.05){homocedasticidad =0} R2[i] =summary(reg.aux)[[8]] i = i +1}p.valor # vemos en que regresiones auxiliares hay relación con los resiudos
if (homocedasticidad ==0){print("Rechazo la hipótesis nula de homocedasticidad")} else {print("No rechazo la hipótesis nula de homocedasticidad")}
[1] "No rechazo la hipótesis nula de homocedasticidad"
Si para los contrastes anteriores ha habido que escribir el código correspondiente, los contrastes de Breusch-Pagan y Goldfeld-Quandt están implementados en la librería lmtest:
# install.packages("lmtest") # sólo hay que instalarlo una vezlibrary(lmtest) # lo cargamos para usarlo
Warning: package 'lmtest' was built under R version 4.2.2
Loading required package: zoo
Warning: package 'zoo' was built under R version 4.2.2
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
bptest(regresion)
studentized Breusch-Pagan test
data: regresion
BP = 4.2476, df = 3, p-value = 0.2359
gqtest(regresion, fraction=1/3, order.by=GNP) # no me fio mucho
Goldfeld-Quandt test
data: regresion
GQ = 2042.6, df1 = 2, df2 = 1, p-value = 0.01564
alternative hypothesis: variance increases from segment 1 to 2
Goldfeld-Quandt test
data: regresion
GQ = 2042.6, df1 = 2, df2 = 1, p-value = 0.01564
alternative hypothesis: variance increases from segment 1 to 2
Los métodos analíticos respaldan las sospechas de que no se incumple la hipótesis básica de homocedasticidad.
Autocorrelación
Detección mediante métodos gráficos
Mediante el gráfico de dispersión de los residuos:
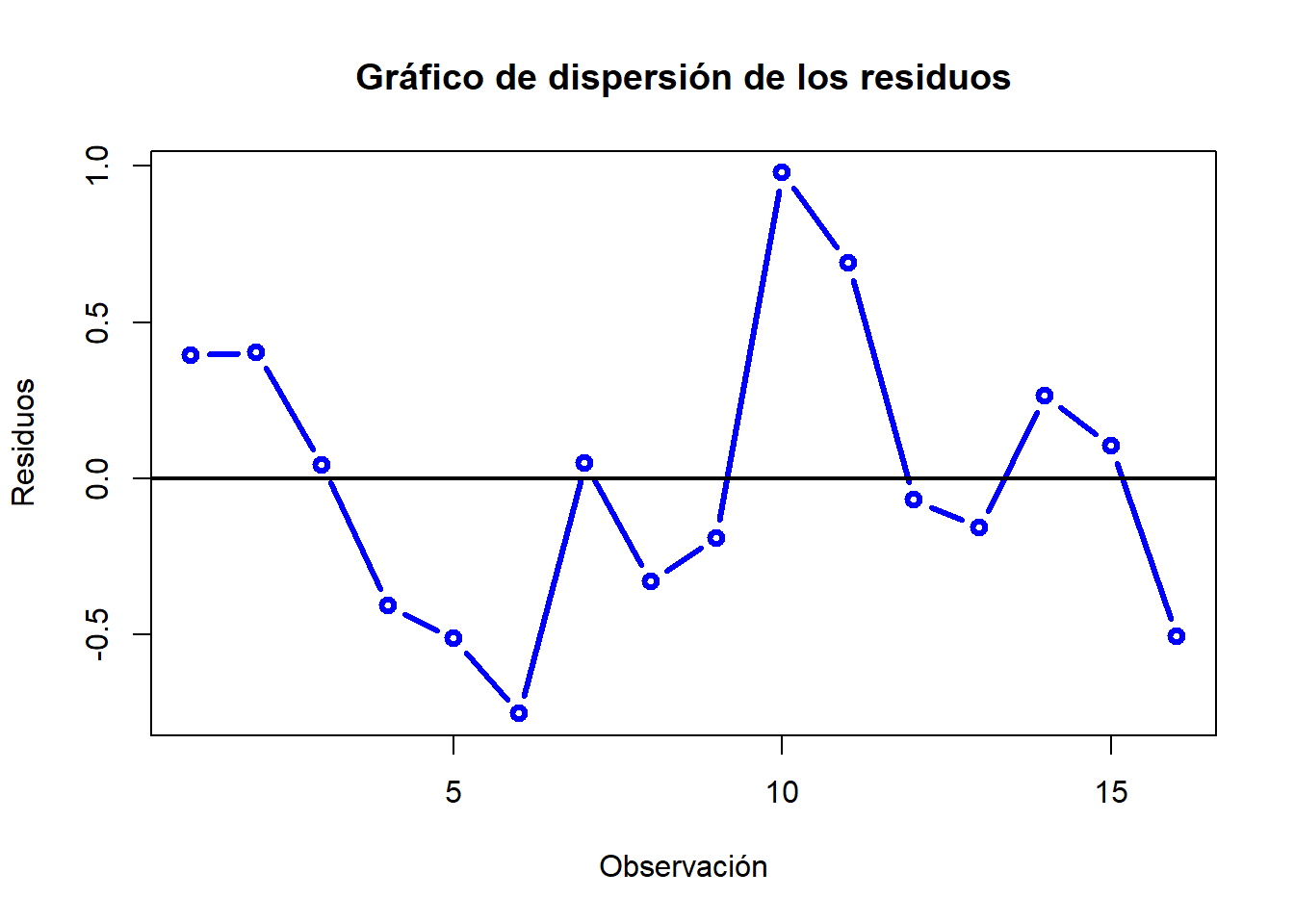
plot(e, type="b", ylab="Residuos", xlab="Observación", col="blue", lwd=3, main="Gráfico de dispersión de los residuos")abline(h=0, col="black", lwd=2)
Debemos buscar rachas de residuos por debajo y por encima del cero (correlación positiva) o alternancia en el signo (correlación negativa). En este caso puede ser que exista correlación positiva.
Mediante el gráfico de dispersión de los residuos frente a un retardo suyo:
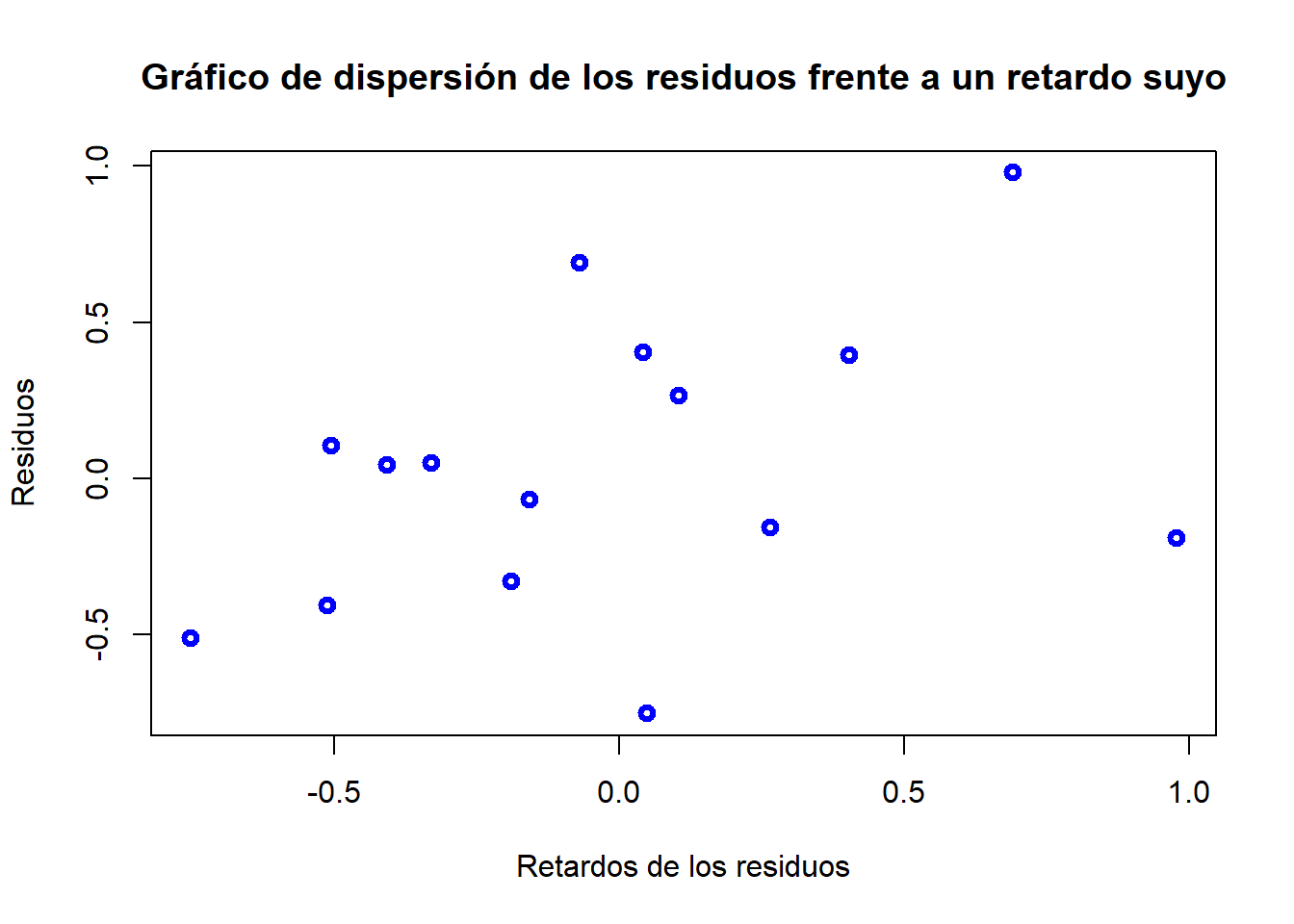
e.r = e[-length(e)] # primer retardo de los residuose = e[-1] # para cuadrar dimensiones quito primera observación de los residuosplot(e,e.r, ylab="Residuos", xlab="Retardos de los residuos", col="blue", lwd=3, main="Gráfico de dispersión de los residuos frente a un retardo suyo")
Una tendencia creciente indicaría correlación positiva y una tendencia decreciente negativa. Este gráfico parece respaldar la suposición anterior de correlación positiva.
Detección mediante métodos analíticos
Mediante el contraste de Durbin-Watson:
# requiere el paquete "lmtest" anteriormente cargadodwtest(regresion)
Durbin-Watson test
data: regresion
DW = 1.1698, p-value = 0.008272
alternative hypothesis: true autocorrelation is greater than 0
El p-valor indica que se rechaza la hipótesis nula de incorrelación. Por otro lado, se puede usar el valor del estadístico de Durbin-Watson para ver en que región cae exactamente a como se hace en clase.
Normalidad
Mediante los contrastes de Kolmogorov-Smirnof, Shapiro-Wilk y Lilliefors aplicados a los residuos:
ks.test(e, pnorm, 0, sd(e))
Exact one-sample Kolmogorov-Smirnov test
data: e
D = 0.14551, p-value = 0.8646
alternative hypothesis: two-sided
shapiro.test(e)
Shapiro-Wilk normality test
data: e
W = 0.96718, p-value = 0.8144
# install.packages("nortest") # sólo hay que instalarlo una vezlibrary(nortest) # lo cargamos para usarlolillie.test(e)
Lilliefors (Kolmogorov-Smirnov) normality test
data: e
D = 0.12398, p-value = 0.7737
En todos los casos el p-valor indica que no se rechaza la hipótesis nula de normalidad. Luego todo el desarrollo teórico basado en esta suposición (inferencia en el modelo de regresión) queda legitimada.
Corrección de las hipótesis básicas del modelo
Corrección de hetrocedasticidad
Suponiendo que se conoce el patrón de dependencia de la varianza de la perturbación aleatoria, \(Var(u) = \sigma^{2} \cdot X_{i}^{h}\), se puede corregir el problema de heterocedasticidad ponderando por \(\frac{1}{\sqrt{X_{i}^{h}}}\). Esta ponderación se puede introducir en la estimación mediante el comando lm usando la opción weights.
Así, por ejemplo, si en el modelo anterior existiera heterocedasticidad según el patrón \(Var(u) = \sigma^{2} \cdot \frac{1}{GNP^{2}}\), la corrección de heterocedasticidad vendría dada por: