momentos.b = function(x, y, r, s, mp.x = mean(x), mp.y = mean(y)){
m = sum(((x-mp.x)^r)*((y-mp.y)^s))/length(x)
return(m)
}
correlacion = function(x, y) {
return(momentos.b(x,y,1,1)/sqrt(momentos(x,2,mean(x))*momentos(y,2,mean(y))))
}
regresion = function(y, x, recta = T){
media.y = mean(y)
media.x = mean(x)
n = length(x)
varianza.x = momentos(x, 2, mp=media.x)
covarianza = momentos.b(x, y, 1, 1)
pendiente = covarianza/varianza.x
origen = media.y - pendiente*media.x
resultados = data.frame(media.y, covarianza, varianza.x, media.x)
ifelse (recta == T, paste("y =", pendiente, "* x +", origen), return(resultados))
}En el post anterior surgía de forma natural la necesidad de relacionar dos variables para enriquecer el análisis individual de cada una de ellas. En tal caso, se estaría hablando de Estadística Descriptiva Bidimensional (la extensión a tres o más variables analizadas de forma simultánea sería inmediata).
A continuación se tienen funciones que permiten calcular los momentos centrados y no centrados de dos variables, el coeficiente de correlación simple y la estimación de una recta de regresión:
Si existe un comando en R que permite calcular la correlación entre dos variables (que no es otro que corr), ¿por qué crear una función que haga lo mismo? La respuesta es muy sencilla, simplemente por motivos pedagógicos. Al igual que para la varianza, R divide por n-1 (siendo n el número de observaciones) en el cálculo de la covarianza. Este hecho hace que al dividir por los estimadores insesgados de las varianzas, este término se cancele y se obtenga el mismo resultado. Aunque suponga trabajo extra, no está de más explicarlo y mostrarlo:
momentos = function(x, r, mp = 0) { # cargamos esta función puesto que es usada en momentos.b
m = sum((x-mp)^r)/length(x)
return(m)
}
set.seed(2022) # para que siempre se realicen los cálculos con los mismos datos aleatorios
x = sample(1:1000, 100)
y = sample(1:1000, 100)
cov(x,y) # las covarianzas son distintas[1] 9925.464momentos.b(x,y,1,1)[1] 9826.209correlacion(x, y) # las correlaciones coinciden[1] 0.1198065cor(x,y) [1] 0.1198065También podríamos escribir una función que aglutine las anteriores y permita con un sólo click el análisis bidimensional de dos variables:
BID = function(x, y, graf = T, recta = T){
covarianza = momentos.b(x,y,1,1)
correlacion = momentos.b(x,y,1,1)/sqrt(momentos(x,2,mean(x))*momentos(y,2,mean(y)))
coef.det = correlacion^2
recta = regresion(y,x,recta)
if(graf == T){plot(x, y, lwd=2, col="blue")}
salida = data.frame(covarianza, correlacion, coef.det, recta)
rownames(salida) = c ("")
return(salida)
}E incluso, otra que realice el unidimensional y bidimensional de forma conjunta:
TC1 = function(x, y, graf = T, recta = T){
todo.x = TODO(x)
todo.y = TODO(y)
bid = BID(x, y, graf, recta)
salida = list(todo.x, todo.y, bid)
names(salida) = c("Descriptivos X", "Descriptivos Y", "Bidimensional")
return(salida)
}Para ilustrar las funciones anteriores, consideremos de nuevo los datos sobre la altura y peso de 50 personas usados en el post anterior:
Altura = c(172, 167, 174, 169, 178, 196, 160, 168, 172, 181, 180, 181, 188, 170, 171,
160, 180, 177, 175, 186, 165, 180, 174, 180, 178, 179, 180, 180, 173, 165,
185, 165, 170, 174, 165, 168, 172, 181, 180, 181, 188, 170, 181, 180, 174,
180, 178, 179, 180, 180)
Peso = c(60, 65, 75, 72, 78, 95, 50, 60, 74, 72, 70, 89, 100, 60, 73, 57,
65, 95, 67, 82, 59, 97, 68, 75, 71, 95, 85, 82, 60, 61, 91, 53,
60, 67, 52, 60, 74, 72, 70, 89, 100, 60, 89, 97, 68, 75, 71, 95, 85, 82) Ahora bien, para simplificar el código, es habitual copiar todas las funciones en un archivo de texto plano (llamado, por ejemplo funciones.txt) y cargar el contenido de su contenido mediante el comando source sin más que especificar:
source("funciones.txt") Para que este comando funciones, el archivo funciones.txt tiene que estar en el directoria de trabajo de la sesión abierta de R. En caso contrario habría que especificar el camino absoluto donde se encuentra el archivo.
Así, mediante el siguiente código se puede realizar un análisis bidimensional del peso y altura de las 50 personas:
BID(Peso, Altura, graf = T, recta = T)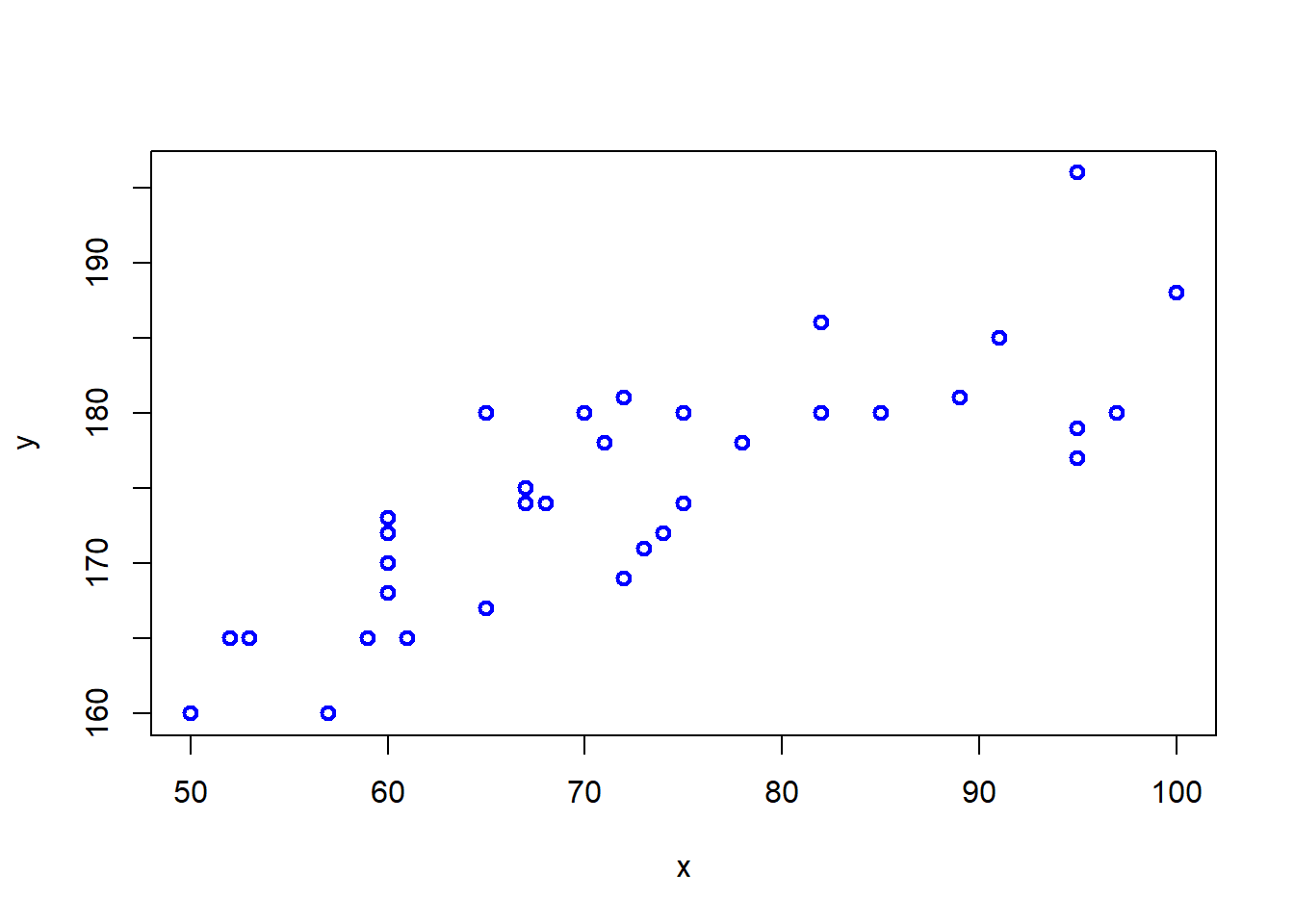
covarianza correlacion coef.det recta
81.188 0.8061609 0.6498954 y = 0.425856454672105 * x + 144.099245514209BID(Altura, Peso, graf = T, recta = F)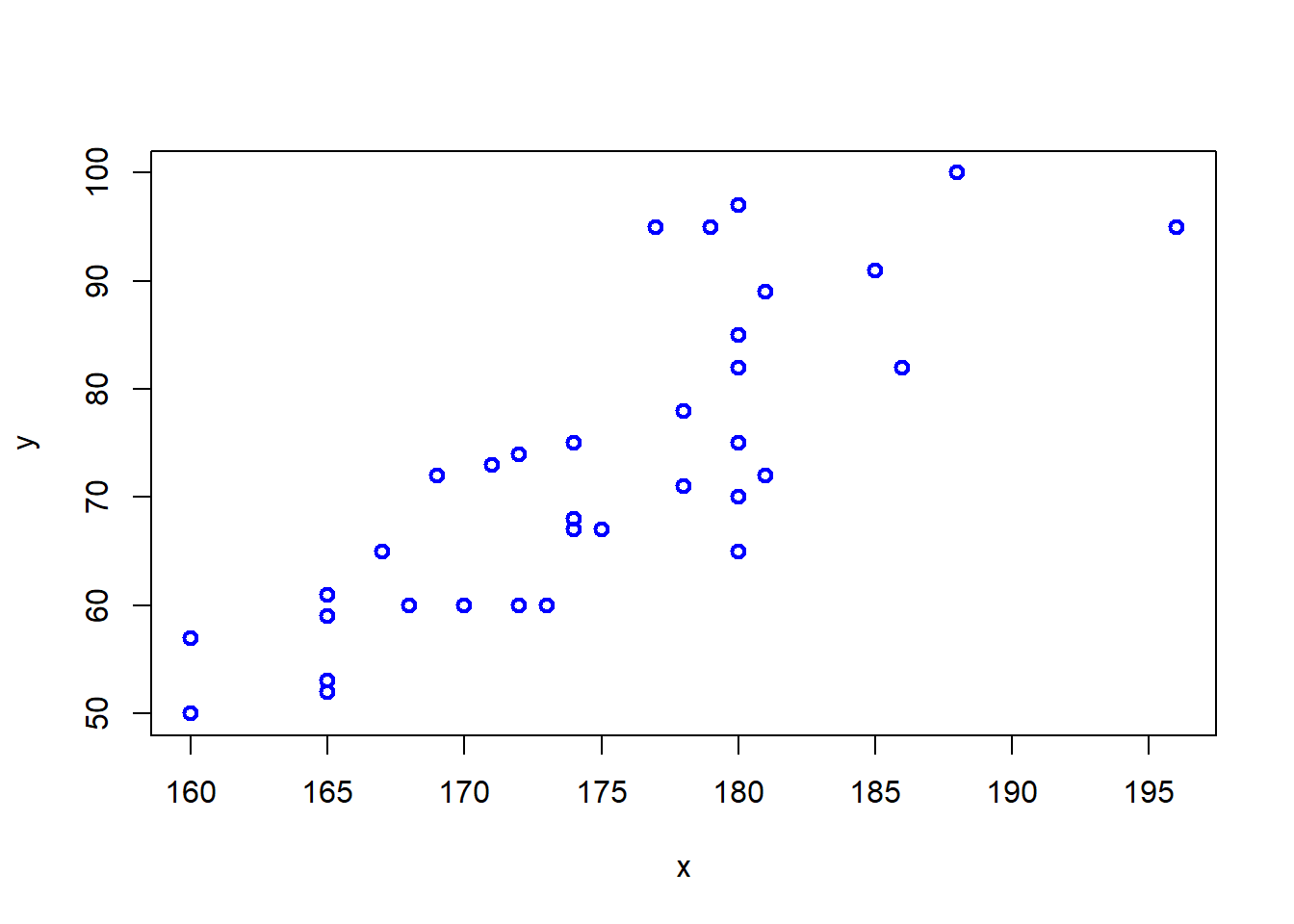
covarianza correlacion coef.det media.y covarianza.1 varianza.x media.x
81.188 0.8061609 0.6498954 74.44 81.188 53.2 175.8O ambos:
TC1(Altura, Peso) # x = Altura, y = Peso 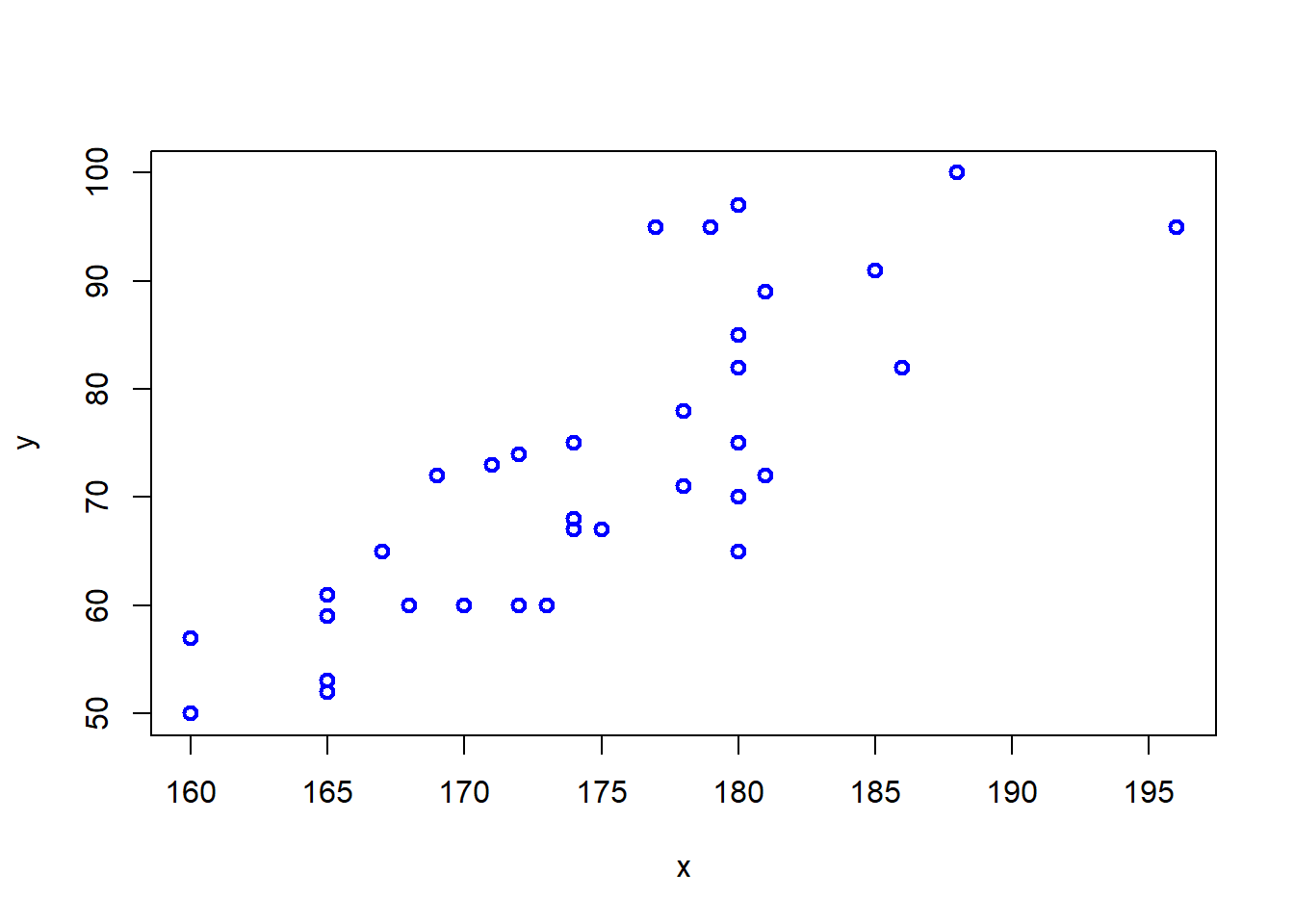
$`Descriptivos X`
n media mediana moda varianza desv.tip Q1 Q3 percentil.alfa minimo
50 175.8 178 180 53.2 7.293833 170.25 180 187.1 160
maximo rango rango.int ca rango.re cv pearson simetria
196 36 9.75 1.225 0.2047782 0.04148938 -0.5758289 -0.02307027
kurtosis gini
0.07680932 0.0229124
$`Descriptivos Y`
n media mediana moda varianza desv.tip Q1 Q3 percentil.alfa minimo maximo
50 74.44 72 60 190.6464 13.80748 62 85 97 50 100
rango rango.int ca rango.re cv pearson simetria kurtosis gini
50 23 2 0.6716819 0.1854846 1.04581 0.2813998 -0.9827826 0.1055884
$Bidimensional
covarianza correlacion coef.det recta
81.188 0.8061609 0.6498954 y = 1.52609022556391 * x + -193.846661654135Se puede observar una alta asociación positiva entre ambas variables, correlación igual a 0.8061, de forma que ambas variables tienen una relación directa: cuando una aumenta/disminuye, la otra también.
Cuando se plantea la recta de regresión, se podrían proponer dos opciones. Sin embargo, aunque desde el punto de vista númerico esto sea posible, desde el punto de vista interpretativo no es así. Lo lógico es estudiar el peso en función de la altura (como se hace en el último comando) y no al revés. Así, por ejemplo, una persona con 185 centímetros debería pesar:
1.52609022556391 * 185 -193.846661654135[1] 88.48003Para finalizar, dejo algún material extra sobre estadística descriptiva unidimensional y bidimensional.