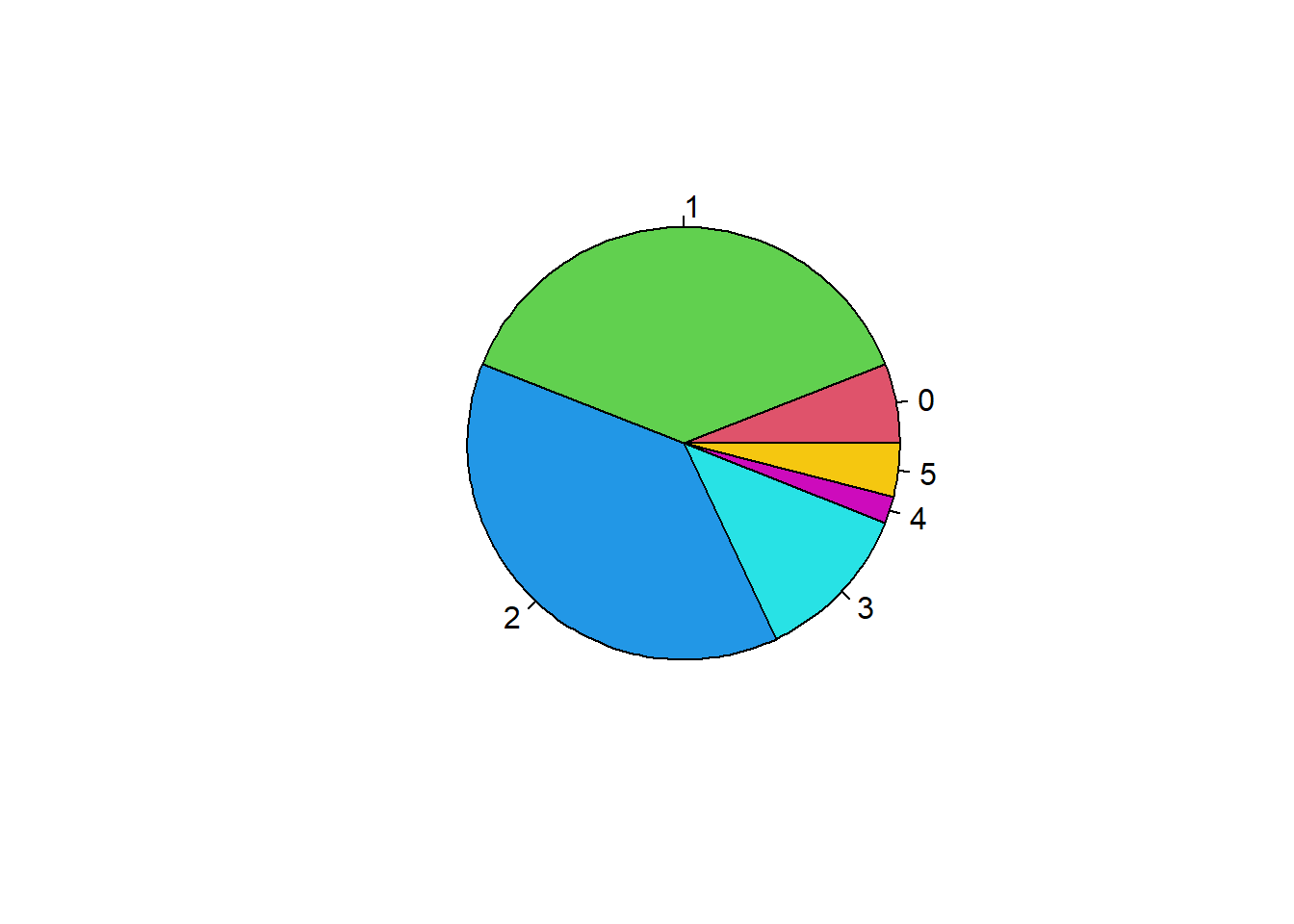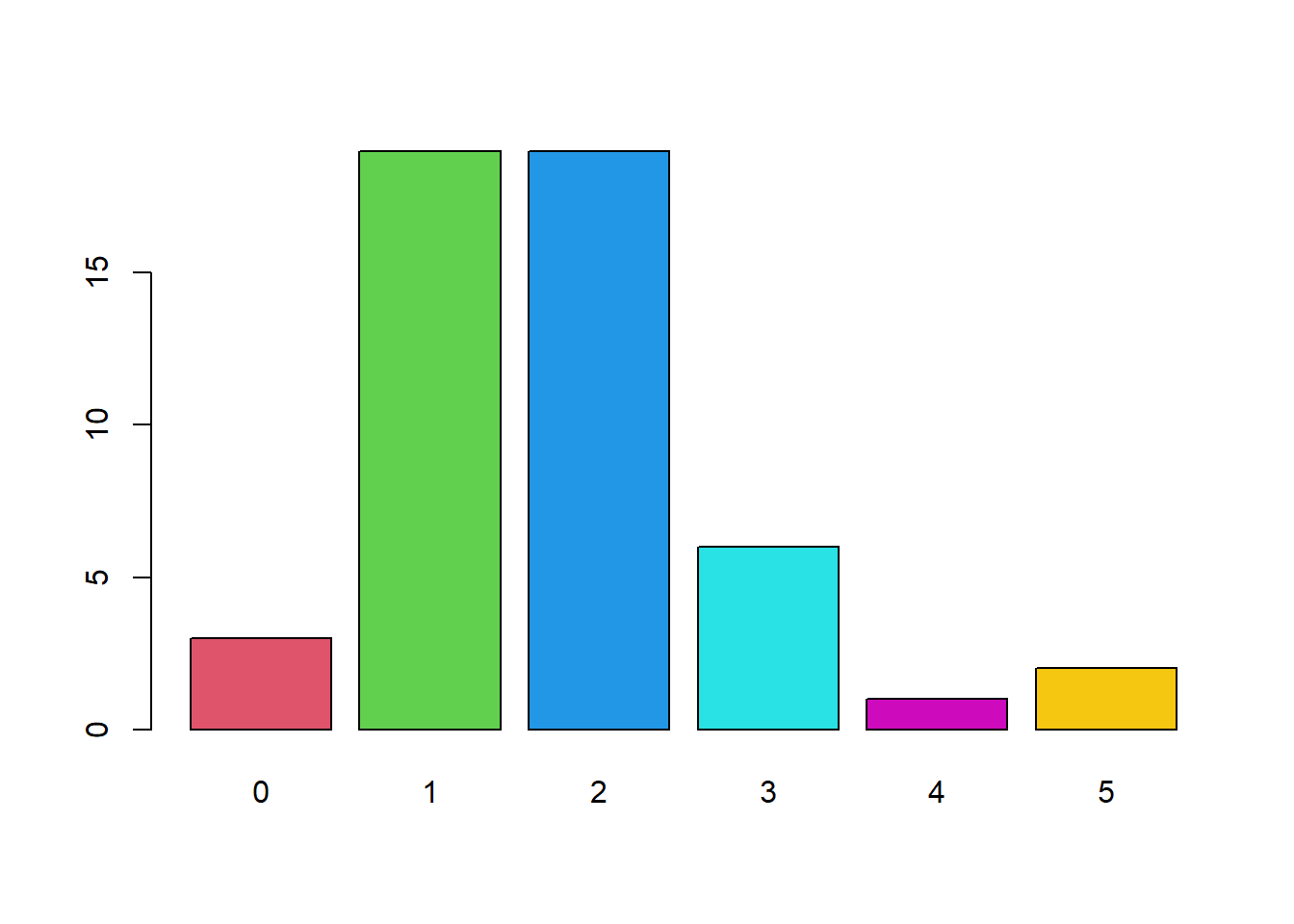El primer paso a realizar cuando se tiene un conjunto de datos es la de realizar un análisis descriptivo de los mismos. De esta forma sabremos lo que tenemos entre manos.
En primer lugar cargamos los datos a usar:
datos =read.table("https://www.ugr.es/local/romansg/material/WebTC1/TC1/datos.txt", header=T, sep=";")names(datos) # nombre de las variables cargadas
attach(datos) # agrego el nombre de las variables a la memoria
Si bien el comando read.table ya había sido usado con anterioridad, es importante destacar que en este caso se incorporan datos disponibles en una dirección web.
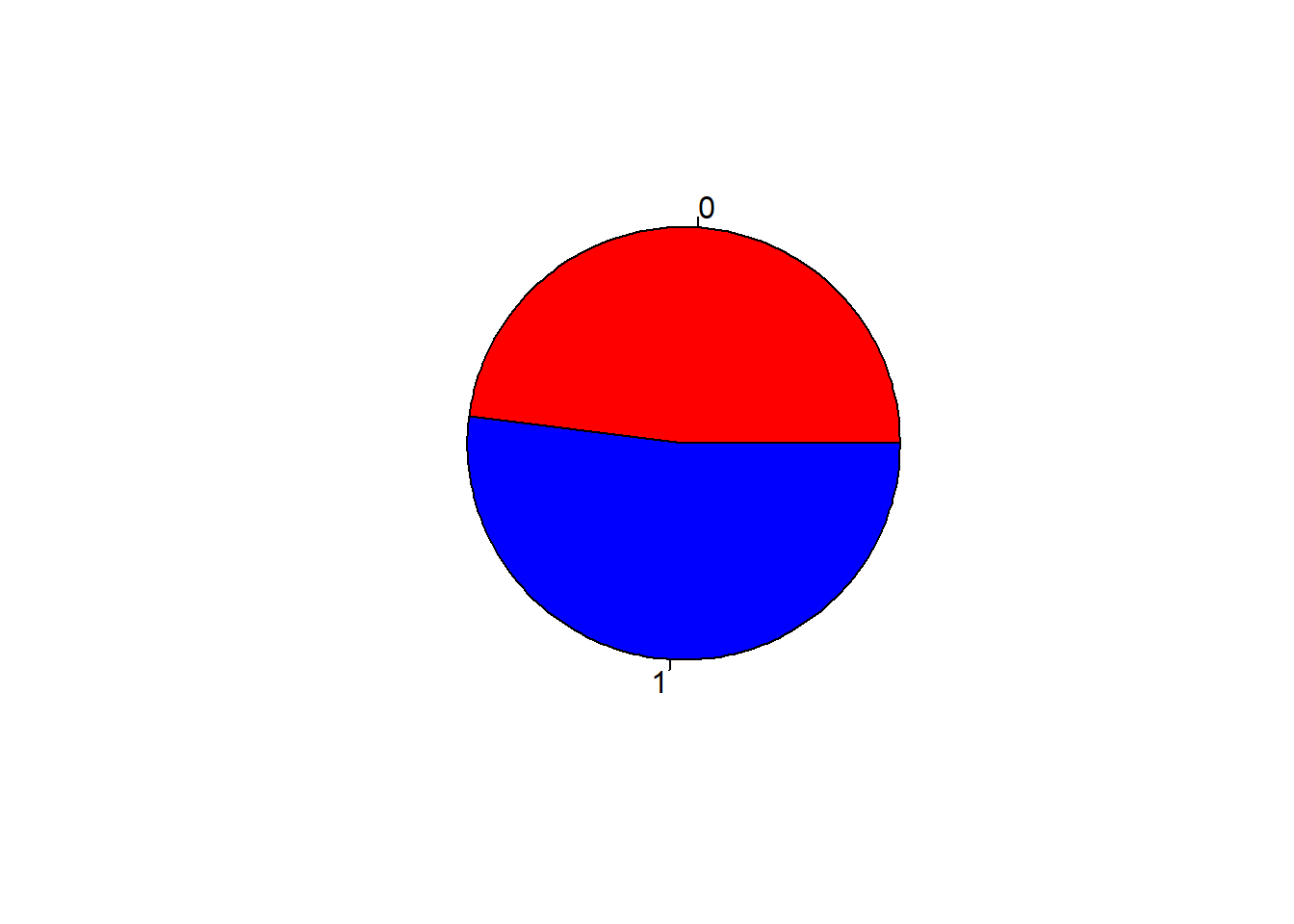
En este caso, se tiene información sobre la altura (medida en centímetros), peso (en kilogramos), edad (en meses), género (1 hombre, 0 mujer), número de hermanos y lateralidad (1 zurdo, 2 diestro).
Antes de empezar con los análisis, vamos a codificar las variables binarias relativas al género y lateralidad:
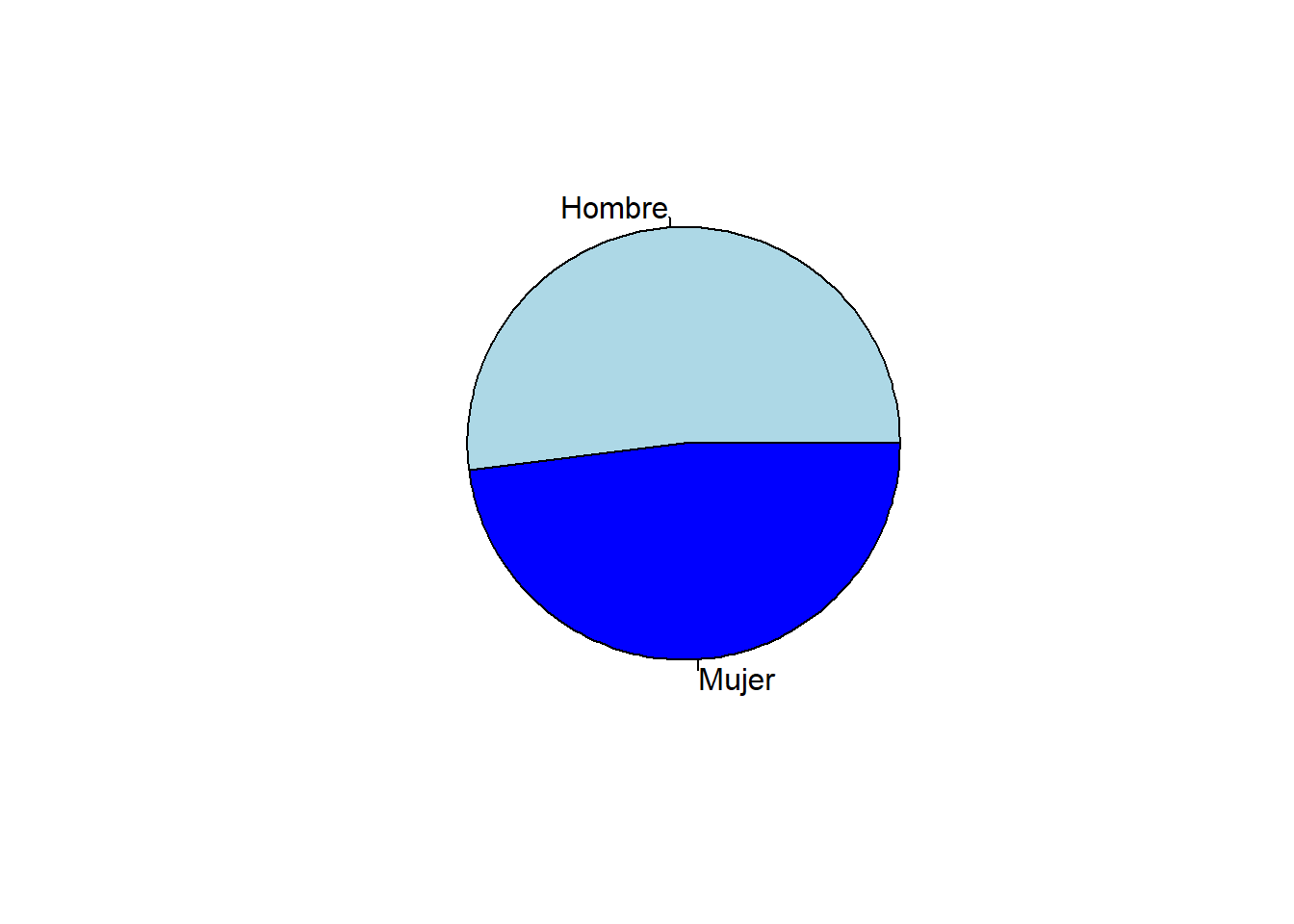
Gen =ifelse(Genero ==1, "Hombre", "Mujer") # genero una variable cualitativa a partir de otra numéricadata.frame(Genero, Gen) # vemos qué se ha hecho
¿Podemos obtener alguna información sin tener conocimientos de estadística? Vamos a intentarlo a partir de algunas representaciones gráficas.
Diagrama de sectores
El diagrama de sectores es una representación gráfica pensada para variables discretas que permite visualizar rápidamente características relacionadas con cada variable. Por ejemplo, es claro que hay más hombres que mujeres o que lo más frecuente es tener 1 ó 2 hermanos, mientras que lo menos son los 4 hermanos:
pie(table(Genero), col=c("red", "blue")) # ¿quién es cero y uno?
pie(table(Gen), col=c("lightblue", "blue")) # la duda anterior la solventamos con el ifelse anterior
pie(table(Hermanos), col=2:7) # ¿tiene sentido esta representación para una variable continua?
Diagrama de barras
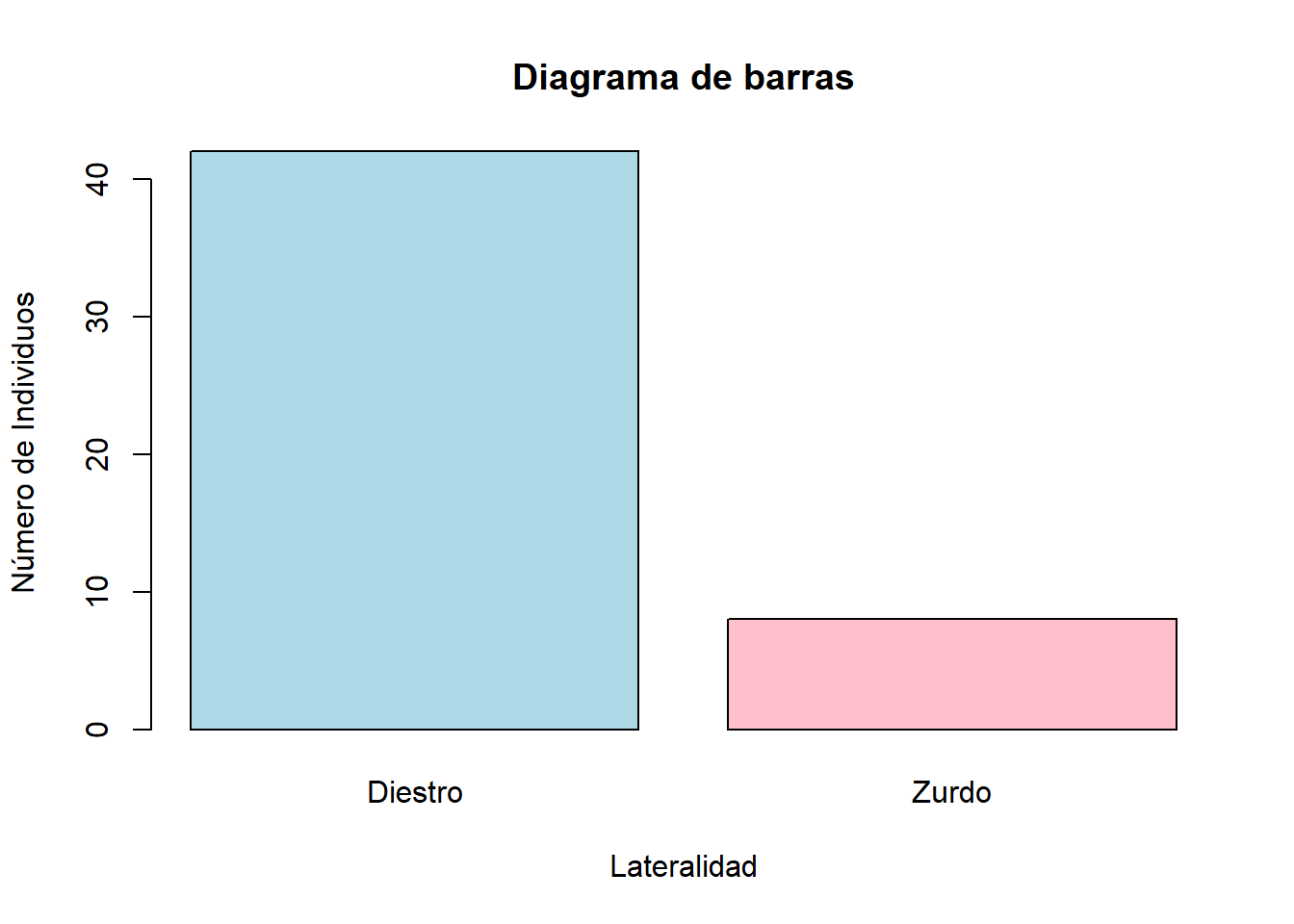
El diagrama de barras es otra representación gráfica con la misma filosofía que el diagrama de sectores:
barplot(table(Late), col=c("lightblue","pink"), xlab="Lateralidad", ylab="Número de Individuos", main="Diagrama de barras")
barplot(table(Hermanos), col=2:7) # ¿tiene sentido esta representación para una variable continua?
En este segundo caso, queda muy claro que hay el mismo número de individuos que tienen 1 y 2 hermanos (a partir del diagrama de sectores podría quedar alguna duda).
Es interesante tener claro la misión de table, col, xlab, ylab o main.
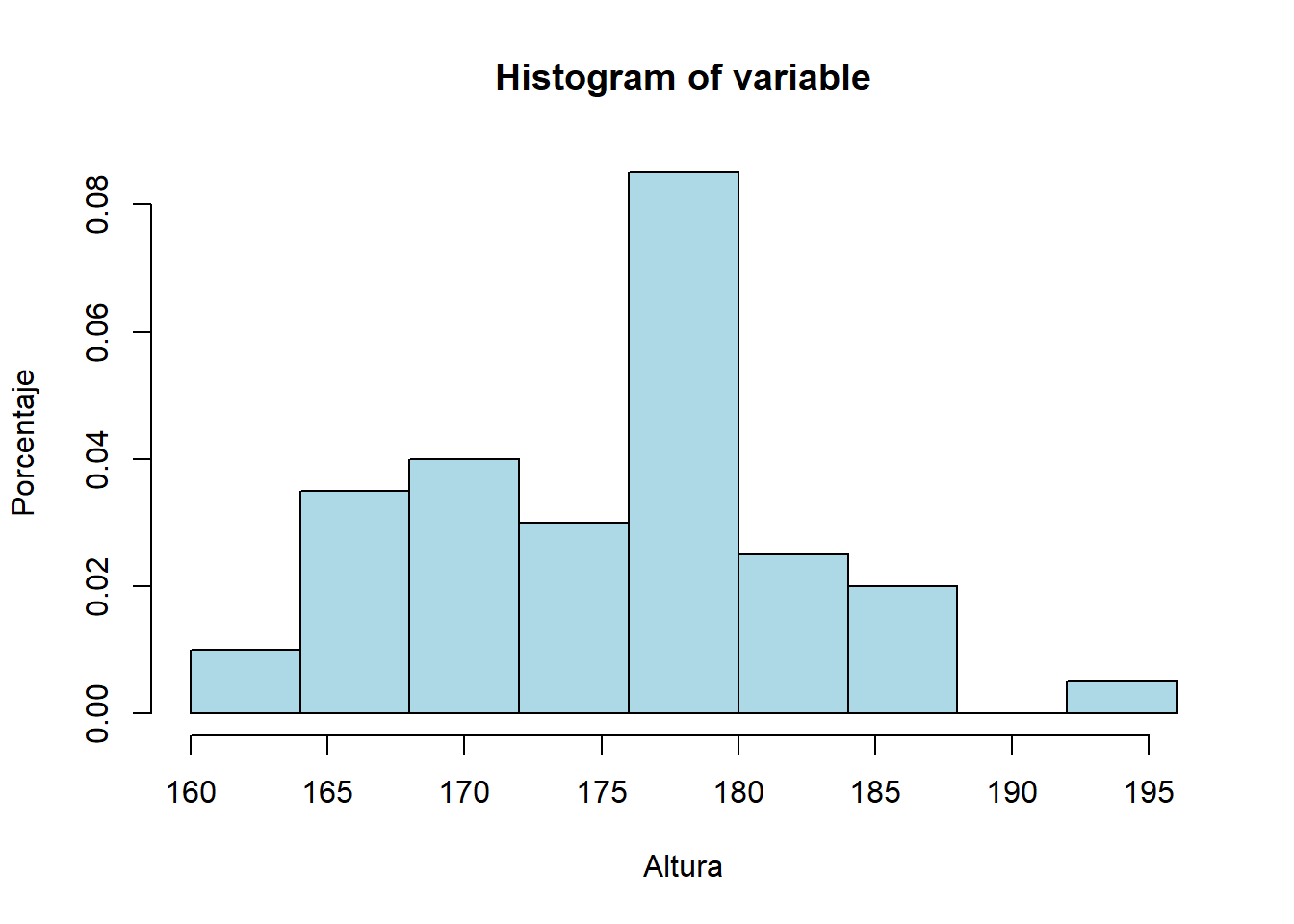
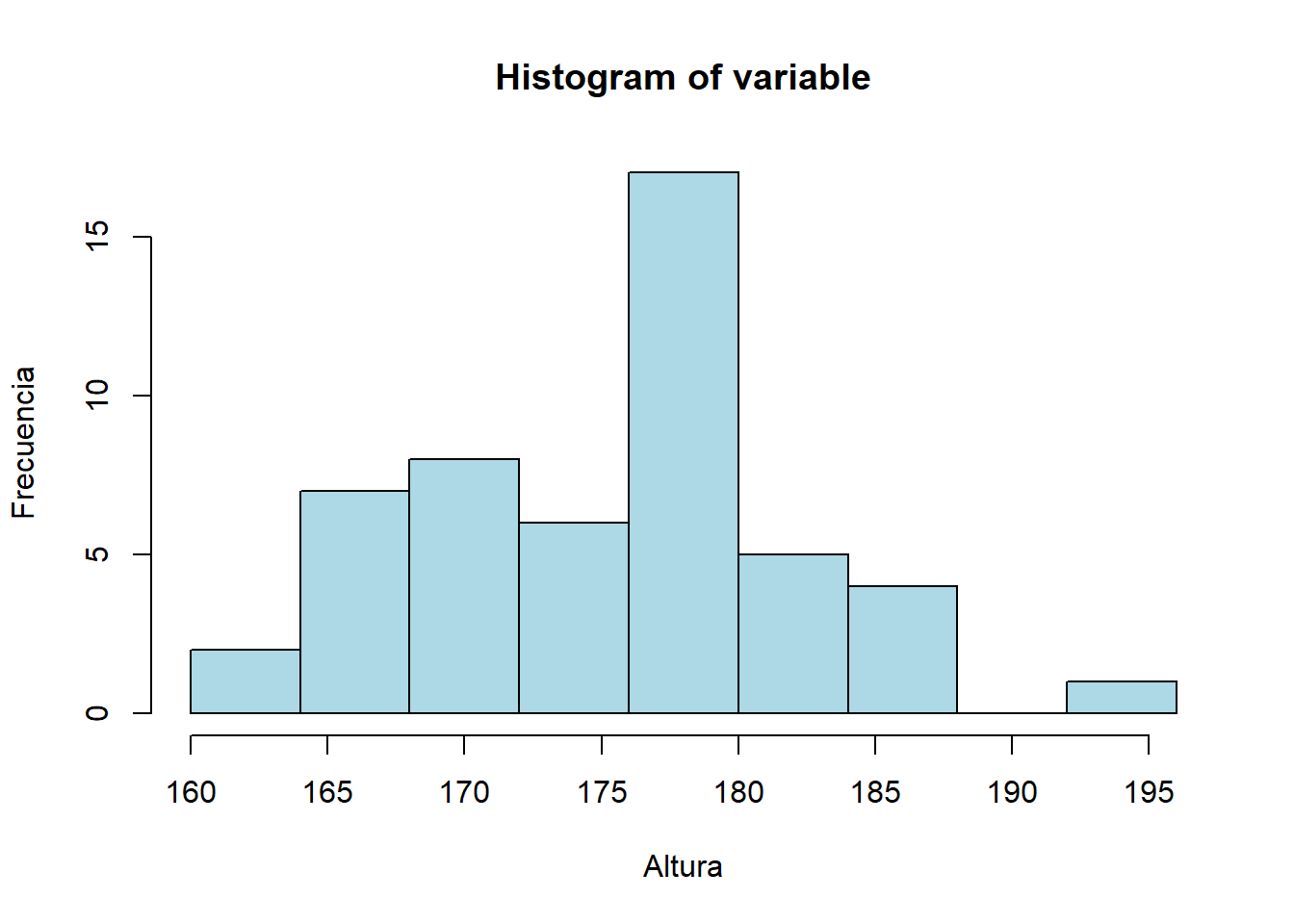
Histograma
Si las representaciones gráficas anteriores están pensadas para variables discretas (con pocas modalidades), en el caso de tener una variable continua, la representación gráfica a usar es el histograma:
variable = Altura # cualquier variable que sea continua minimo =min(variable) maximo =max(variable) rango = maximo - minimo intervalos =9# número de intervalos de igual amplitud que quiero crearhist(variable, breaks=seq(minimo, maximo, rango/intervalos), col="lightblue", freq=F, xlab="Altura", ylab="Porcentaje")
Mediante la opción freq se controla si en el eje vertical se representa la frecuencia relativa de cada modalidad (porcentaje) o absoluta (número de).
A partir de esta representación nos podemos hacer una idea de qué valores son más/menos frecuentes y en qué zona se encuentran.
Diagrama de Tallo y Hojas
Mediante esta representación gráfica se obtienen resultados similares al histograma, con la ventaja de que se observan todos y cada uno de los datos:
stem(Altura)
The decimal point is 1 digit(s) to the right of the |
16 | 00
16 | 55557889
17 | 000122234444
17 | 5788899
18 | 0000000000011111
18 | 5688
19 |
19 | 6
Aunque pueda usarse para variables discretas también, pierde toda su potencia:
stem(Genero)
The decimal point is 1 digit(s) to the left of the |
0 | 000000000000000000000000
2 |
4 |
6 |
8 |
10 | 00000000000000000000000000
¡Ojo! Hay que tener claro que el software informático va a calcular todo lo que le pidamos, independientemente de si es adecuado o no.
Otro ejemplo de que la potencia sin control no tiene sentido:
pie(Edad)
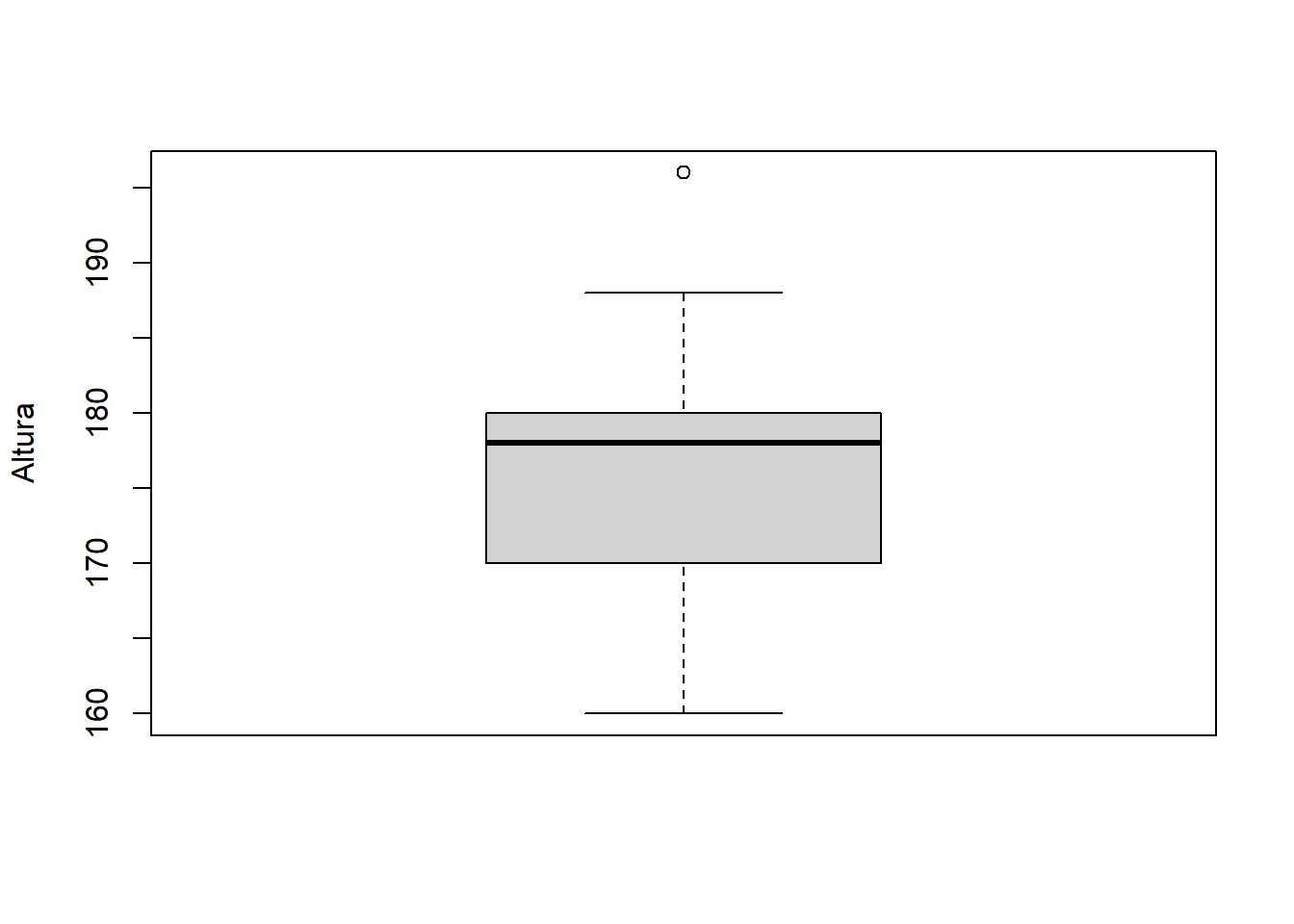
Diagrama Box-Whisker
Todo lo que se diga sobre esta representación gráfica es poco. En este punto inicial, la utilidad más evidente es la detección de datos anómalos, es decir, datos que se comportan de forma manifiestamente distinta al resto:
boxplot(variable, ylab="Altura") # ¿hay algunos datos anómalos?
Cuando existen este tipo de datos (también conocidos como outliers), es interesante comprobar a qué se deben. Podrían deberse simplemente a un error de transcripción fácilmente subsanable.
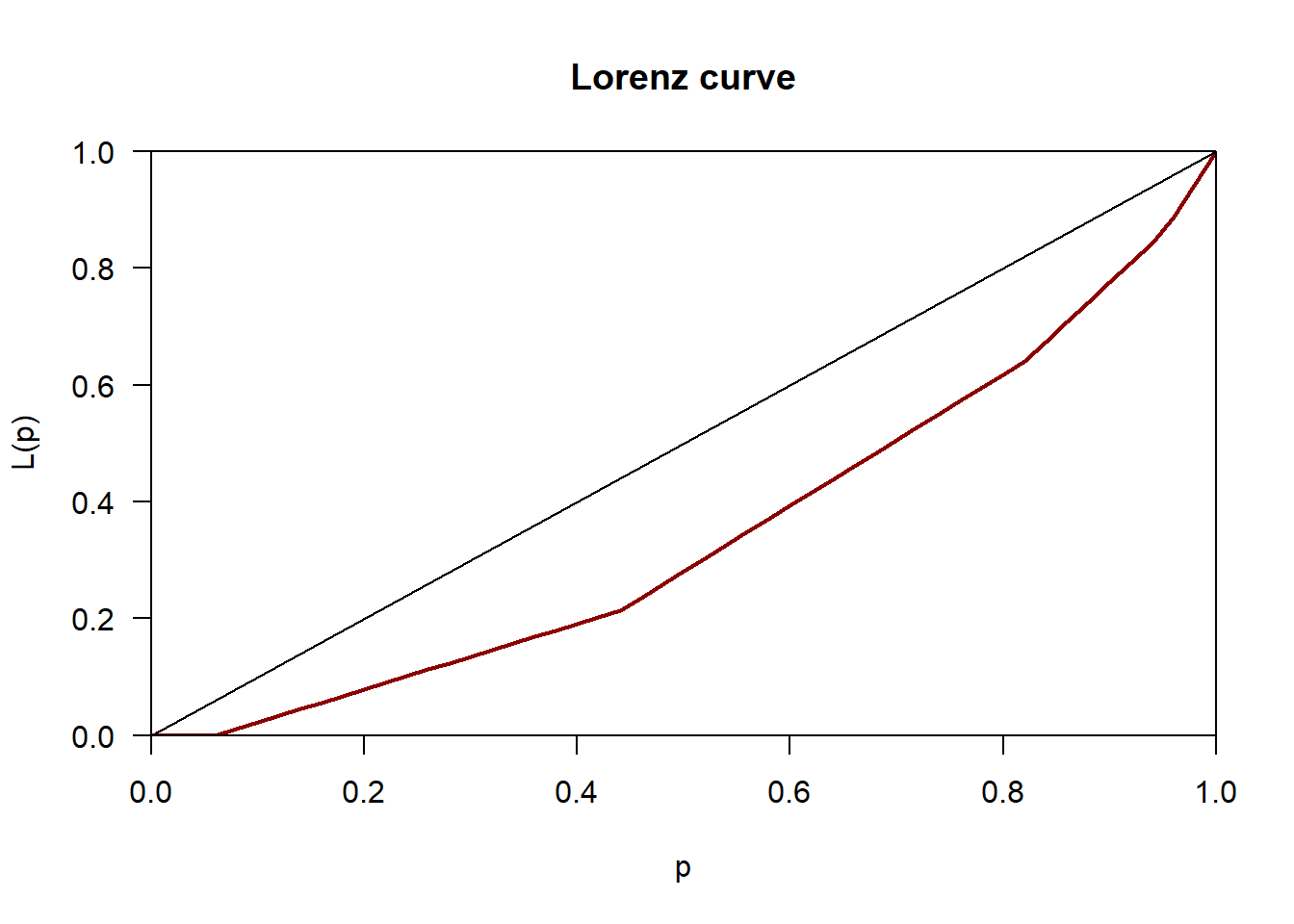
Curva de Lorenz
La última representación que vamos a comentar es la curva de Lorenz:
# install.packages("ineq") # sólo hay que instalarlo una vez library(ineq) # para usarlo hay que cargarlo en la memoriaplot(Lc(Hermanos), col="darkred", lwd=2)