En una de esas maravillosas conversaciones de bar post pachanga, unos amigos me preguntaron cuál sería la anotación más frecuente en la liga ACB, siendo su hipótesis de partida que es cero. ¿Tendrán razón?
En primer lugar, cargamos los datos y vemos lo que tenemos:
library(readxl)datos <-read_excel("SUPERCOPAhasta2024.xlsx", sheet ="datos")vistazo =head(datos)library(knitr)kable(vistazo, align ="c", caption ="Visualización de los datos: unas pocas observaciones")
Visualización de los datos: unas pocas observaciones
Temporada
Apodo
Fecha
Fase
Resultado
Nombre
Min
Seg
Ptos
Equipo
2004
LS4
20040925
Semifinales
0
L. Scola
9
20
2
Baskonia
2004
TH6
20040925
Semifinales
0
T. Hansen
30
9
5
Baskonia
2004
JC8
20040925
Semifinales
0
J. Calderón
40
0
9
Baskonia
2004
SV9
20040925
Semifinales
0
S. Vidal
28
15
5
Baskonia
2004
AA14
20040925
Semifinales
0
A. Arzallus
NA
NA
NA
Baskonia
2004
KD18
20040925
Semifinales
0
K. David
29
43
18
Baskonia
Concretamente, se tiene el año en el que se disputa el partido (incluso con la fecha concreta), el nombre del jugador (junto a una abreviatura que lo identifica y equipo al que pertenece), si el partido se ha jugado en semifinales o en la final, el resultado final del partido (1 victoria, 0 derrota), el tiempo jugado y los puntos anotados.
Como se observa que hay algunos datos perdidos debido a jugadores que no han llegado a disputar el partido, lo primero que hacemos es eliminar dichos datos perdidos y, además, me quedo con aquellas variables que voy a usar finalmente:
attach(datos)Tiempo =round(Min + Seg/60, digits =0)jugadores =data.frame(Apodo, Nombre, Tiempo, Ptos)jugadores = jugadores[!is.na(Tiempo),] # quitos los datos perdidos en TIEMPO#head(jugadores)
Se puede observar que se ha creado una variable Tiempo que aglutina a los minutos y segundos, la cual ha sido redondeada para simplicar las cuentas posteriores.
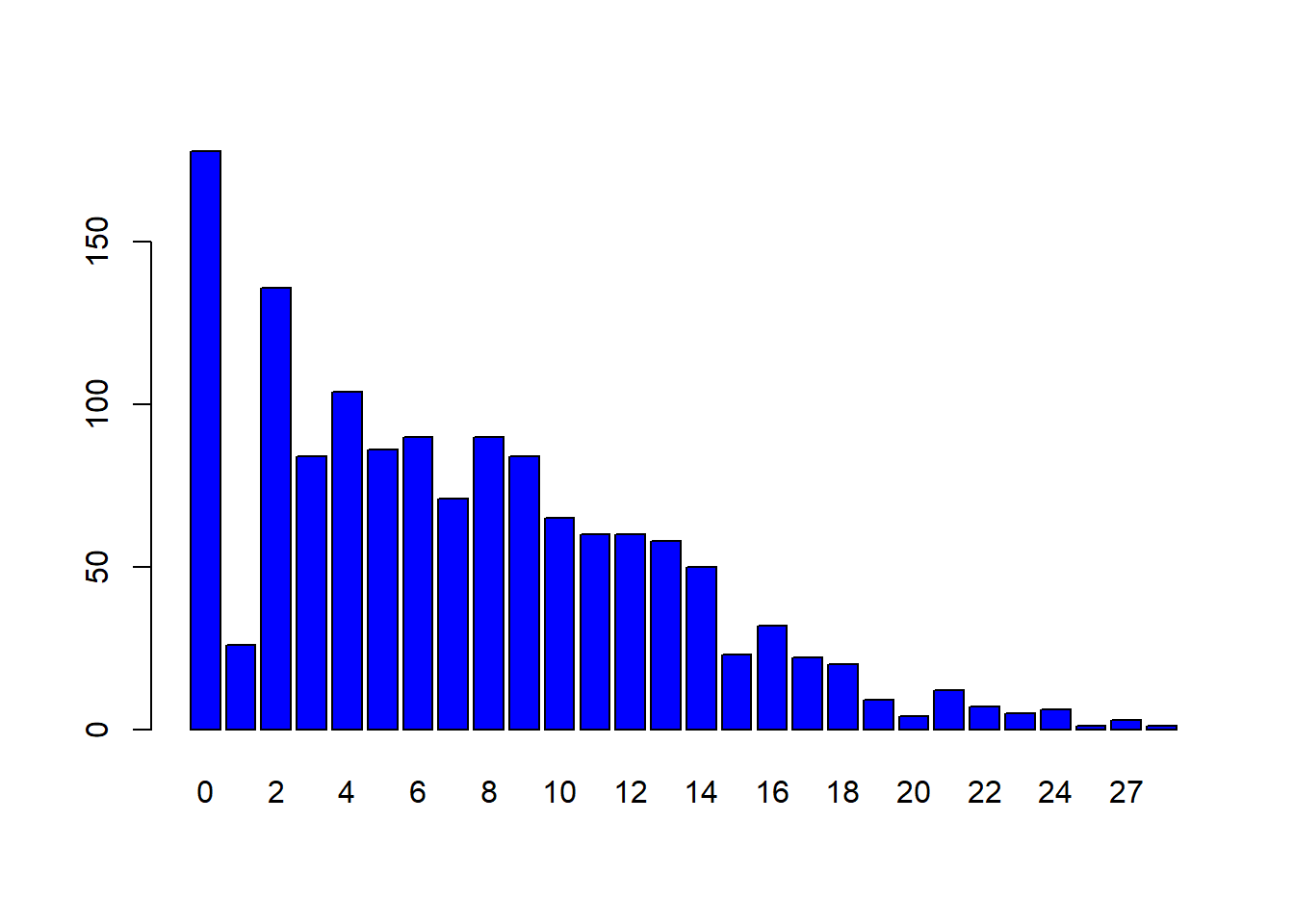
Así, que ya se está en condiciones de dar respuesta a la pregunta inicial. Gráficamente se ve claro que sí, que la anotación más frecuente es no anotar:
barplot(table(jugadores$Ptos), col="blue")
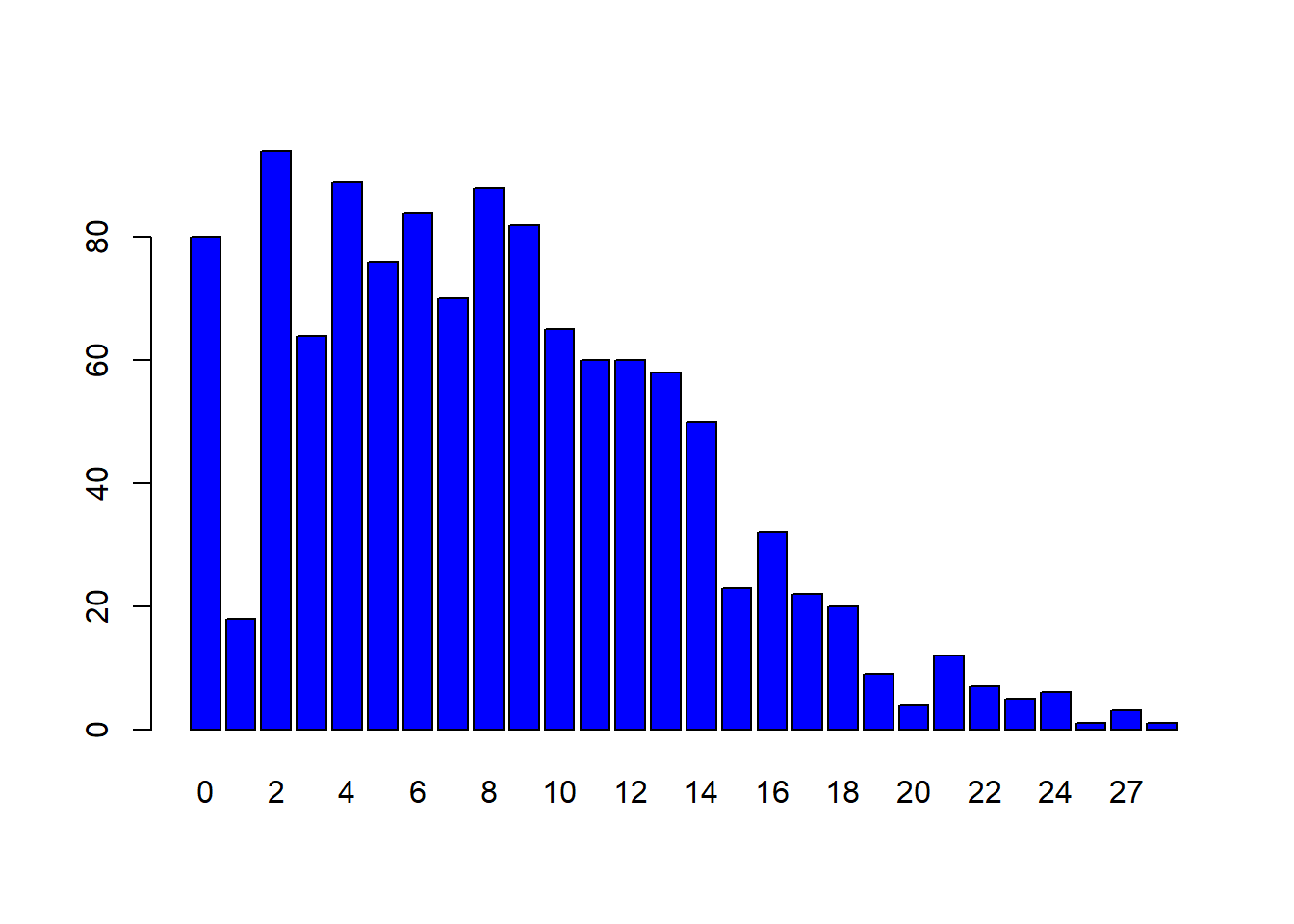
Pero juguemos un poquito con los datos. ¿Qué ocurrre si restringimos en función del tiempo jugado? Por ejemplo, si exigimos haber disputado al menos 10 minutos la situación cambia:
Vamos a automatizarlo para que calcule la moda suponiendo que se ha jugado al menos 0, 1, 2, 3,…, 39 minutos:
library(modeest)moda_min =integer()moda_max =integer()i =1for (tpo in0:39){ datos_finales =filter(jugadores, jugadores$Tiempo > tpo) moda =mlv(datos_finales$Ptos, method ="mfv") # depende de la libreria 'modeest' moda_min[i] =min(moda) moda_max[i] =max(moda) i = i +1}
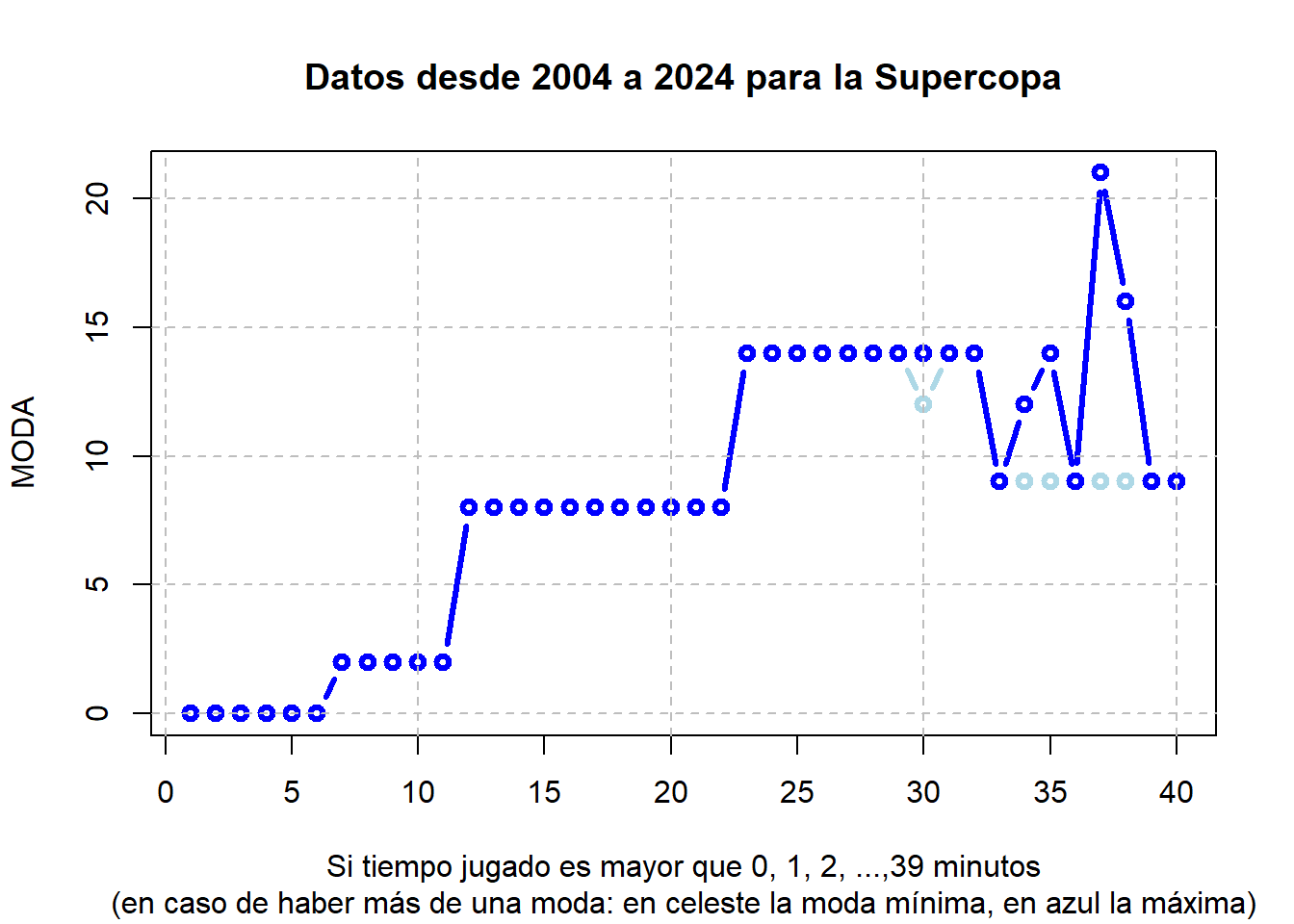
Gráficamente se observa que la anotación más frecuente es el cero cuando se juegan 6 o menos minutos. Cuando se juega entre 12 y 22 minutos la anotación más frecuente es 8 puntos, la cual sube a los 14 puntos cuando se disputan entre 23 y 32 minutos:
modas =ts(cbind(moda_min, moda_max), start =1)plot(modas, plot.type="single", col=c("lightblue", "blue"), xaxt ="n", type="b", ylab="MODA", xlab="Si tiempo jugado es mayor que 0, 1, 2, ...,39 minutos", lwd="3", main="Datos desde 2004 a 2024 para la Supercopa", sub="(en caso de haber más de una moda: en celeste la moda mínima, en azul la máxima)")axis(1, xaxp =c(0, 40, 8))#grid(nx = 7, ny = NULL, lty = 2, col = "gray", lwd = 1)grid(nx =NULL, ny =NULL, lty =2, col ="gray", lwd =1)
Es curioso observar que cuando se juegan al menos 33 minutos, el rendimiento baja. Al menos en términos de la anotación. A partir de los 33 minutos jugados se tiene que el valor más frecuente de anotación es normalmente inferior a los 14 puntos.
Adviértase también que cada vez hay menos jugadores que verifican la condición impuesta en cuanto a los minutos jugados (por ejemplo, sólo 10 jugadores han disputado más de 36 minutos en la historia de la Supercopa), por lo que tiene sentido encontrar en los valores finales situaciones con más de una moda.
¿Qué pasará con datos de la liga ACB?
Y, ¿para qué sirve todo esto?
Desde el punto de vista de la Estadística, la moda es una característica de posición central que ofrece información resumida de toda la población en un único dato (al igual que la media, esa seguro que la conocemos). En este caso, estamos recabando informacion sobre el dato que más veces se repite, el más frecuente.
Pero es que además, este dato lo podemos usar para hacernos una idea de mi posición con respecto al resto. De forma que si el jugador considerado como el anotador de mi equipo disputa entre 25 y 30 minutos por partido (en la Supercopa) y su anotación es inferior a los 14 puntos, tenemos en este post evidencia de un rendimiento inferior al más frecuente. Vamos, que le podemos apretar las tuercas.