Es evidente que es de vital importancia conocer el impacto de un jugador en un partido de baloncesto. De las distintas medidas que se tienen para cuantificar esto, seguramente destaque el porcentaje de usabilidad, el cual se calcula (ver, por ejemplo, el glosario de Basketball-Reference) como: \[USG\% = 100 \cdot \frac{1}{\frac{T_J}{T_E/5}} \cdot \frac{TCI_J + 0.44 * T1I_J + BP_J}{TCI_E + 0.44 * T1I_E + BP_E},\] donde \(TCI\) denota a los tiros de campo intentados, \(T1I\) los tiros libres intentados, \(BP\) los balones perdidos, \(T_E\) el tiempo de partido (si no hay prórrogas, 200 minutos) y \(T_J\) los minutos jugados. Los subíndices \(J\) y \(E\) hacen referencia a los jugadores y equipo, respectivamente.
Analizando la expresión anterior, se tiene que:
El denominador \(TCI_E + 0.44 * T1I_E + BP_E\) cuantifica el número de acciones que se toman en el ataque de un equipo.
El término \(\frac{T_J}{T_E/5}\) determina el porcentaje de tiempo que está un jugador en pista.
Por tanto, el producto de ambas determina el número de acciones que se producen en un partido mientras que éste está en pista.
Por otro lado:
\(TCI_J + 0.44 * T1I_J + BP_J\) cuantifica el número de acciones que se toma en ataque un jugador.
Al dividir este factor por el número de acciones que se producen en un partido mientras que un jugador está en pista, y multiplicar el resultado por 100, se obtiene el porcentaje de acciones tomadas por un jugador mientras que éste está en pista.
Ahora bien, creo que esta medida puede completarse considerando que:
Un jugador también finaliza jugada (que no ataque, ver el post sobre desgranando el juego) cuando recibe una falta personal y cuando da una asistencia. Puesto que dar una asistencia significa regalar una canasta consideramos que en cierto modo estamos finalizando jugada.
Planteando cuantificar las jugadas que se finalizan con éxito, es decir, no es lo mismo hacer un tiro de campo que anotar un tiro de campo. Si se considera que un jugador finaliza una jugada cuando intenta un tiro de campo, recibe una falta personal pierde un balón o da una asistencia, se considerará que la finaliza con éxito cuando convierte un tiro de campo, recibe una falta o da una asistencia. Con los datos del primer caso, se puede obtener el porcentaje de posesiones finalizadas por un jugador (%PosFJ); mientras en el segundo caso, el porcentaje de posesiones finalizadas con éxito (%PosFJE).
\[\%PosFJ = \frac{TCI_J + FPR_J + BP_J + Asis_J}{PosJ} \cdot 100,\]\[\%PosFJE = \frac{TCC_J + FPR_J + Asis_J}{TCI_J + FPR_J + BP_J + Asis_J} \cdot 100.\] donde \(PosJ\) son el número de posesiones disfrutadas por el equipo mientras el jugador está en pista, que se calcula como: \[PosJ = \frac{(TCI_E + 0.4 T1I_E + BP_E) \cdot T_J}{T_E/5}.\]
Para ilustrar los conceptos anteriores, voy a usar los datos de todos los jugadores de la Liga Endesa en su Temporada 2022-23 que han jugado en las 21 primeras jornadas:
library(readxl)datos <-read_excel("JugadoresDECISIONES.xlsx", sheet ="datos")attach(datos)vistazo =head(datos)library(knitr)kable(vistazo, align ="c", caption ="Visualización de los datos que tenemos: unas pocas observaciones")
Visualización de los datos que tenemos: unas pocas observaciones
Quinteto
Apodo
Fecha
Jornada
Local
Resultado
Nombre
PosJ
PosFJ
PosFJE
PorcPosFJ
PorcPosFJE
USGporc
0
MF2
20220928
1
1
0
M. Fjellerup
31.64458
9
4
28.44089
44.44444
28.09530
1
EV4
20220928
1
1
0
E. Vila
53.85067
10
4
18.56987
40.00000
16.50980
1
KT5
20220928
1
1
0
K. Taylor
57.10658
24
16
42.02668
66.66667
25.87831
0
PF7
20220928
1
1
0
P. Figueras
40.02217
9
4
22.48754
44.44444
17.27778
0
RP8
20220928
1
1
0
R. Prkacin
21.95000
6
1
27.33485
16.66667
22.50225
0
QC10
20220928
1
1
0
Q. Colom
39.32708
13
9
33.05610
69.23077
14.76985
De los datos disponibles, destacar los referentes al apodo/nombre de los jugadores, al número de posesiones que se disputan mientras que están en pista (PosJ), las que finalizan (PosFJ) y las que finalizan con éxito (PosFJE). Ésta últimas permiten calcular tanto %PosFJ como %PosFJE.
Lo que vamos a hacer en primer lugar es calcular la media de %PosFJ y %PosFJE para cada jugador. También se calcula el número de partidos jugados por cada uno:
media <-function(x) mean(x, na.rm=TRUE) # creo una función que calcule la media ignorando los datos faltantes para que sea usada en tapply attach(datos) PorcPosFJ_Jugadores =tapply(PorcPosFJ, Nombre, media) PorcPosFJE_Jugadores =tapply(PorcPosFJE, Nombre, media) USGporc_Jugadores =tapply(USGporc, Nombre, media) partidos =table(Nombre)detach(datos)
Una vez se tiene esta información, la guardamos en un objeto llamada decisiones y, a continuación, se filtran los datos considerando aquellos jugadores que cumplen una característica en concreto:
En este caso, se tienen aquellos jugadores que finalizan al menos el 35% de las posesiones que se juegan mientras que están en pista y lo hacen con un porcentaje de éxito de al menos el 50%. Igualmente se exige que hayan disputado un mínimo de 10 partidos:
vistazo = datos_finales[,c(1:3,5)]colnames(vistazo) =c("%PosFJ", "%PosFJE", "USG%", "Partidos")kable(vistazo, align ="c", caption ="Visualización de los datos finales: unas pocas observaciones")
Visualización de los datos finales: unas pocas observaciones
%PosFJ
%PosFJE
USG%
Partidos
A. Feliz
35.61138
64.11329
19.92716
21
A. Tomic
40.13157
66.96117
24.92194
21
C. Higgins
36.37489
65.05229
24.58911
12
C. Jones
39.82838
62.49129
21.75581
20
D. Bender
40.91816
59.83706
27.55383
11
D. Brizuela
39.07884
55.93991
24.98426
19
D. Musa
36.76048
65.19383
24.03685
21
D. Pérez
36.51907
58.31018
15.66245
20
D. Thompson
39.32742
67.00733
18.99664
21
F. Ferrari
38.07126
50.87350
19.76843
20
J. Harding
36.79917
53.96966
24.79218
18
J. Harper
39.43701
51.13491
21.95475
14
K. Perry
36.30916
62.50246
22.11812
21
K. Prepelic
37.26915
55.80782
20.08231
21
K. Robertson
37.25933
54.30781
24.51953
12
L. Hakanson
35.94340
61.38621
20.63077
19
L. Westermann
39.51235
52.53715
18.51805
17
M. Howard
43.43138
50.32005
29.73622
20
M. Huertas
46.20942
61.50144
22.56525
20
N. Laprovittola
39.27613
59.16550
21.84572
20
Q. Colom
36.77544
56.72501
19.05379
21
R. Jokubaitis
35.12299
63.03960
17.80500
21
S. Evans
41.67295
60.22886
23.23821
21
T. Trice
38.51710
56.63688
23.96577
21
De la representación de %PosFJ frente %PosFJE de los 24 jugadores seleccionados obtenemos que el jugador que más posesiones finaliza es M. Huertas (Tenerife); mientras que el que mayor porcentaje de posesiones finaliza con éxito es D. Thompson (Baskonia), seguido de cerca por A. Tomic (Joventut):
PosFJ = datos_finales[,1]PosFJE = datos_finales[,2]plot(PosFJ, PosFJE, xlab="% de posesiones finalizadas", ylab="% de posesiones finalizadas con éxito", lwd=3, col="blue", main="Liga ACB - Temporada 2022/23 - Jornadas 1 a 21", xlim=c(min(PosFJ)-1, max(PosFJ)+1), ylim=c(min(PosFJE)-1, max(PosFJE)+1))text(PosFJ, PosFJE, labels =rownames(datos_finales), col="black", pos=1)abline(v=mean(PosFJ), col="red", lwd=2)abline(h=mean(PosFJE), col="red", lwd=2)grid(nx =NULL, ny =NULL, lty =2, col ="gray", lwd =2)
El tener en cuenta a las asitencias, hace pensar en el predominio de los jugadores exteriores en esta estadística, lo que da aún mayor valor a la presencia de A. Tomic entre los mejores.
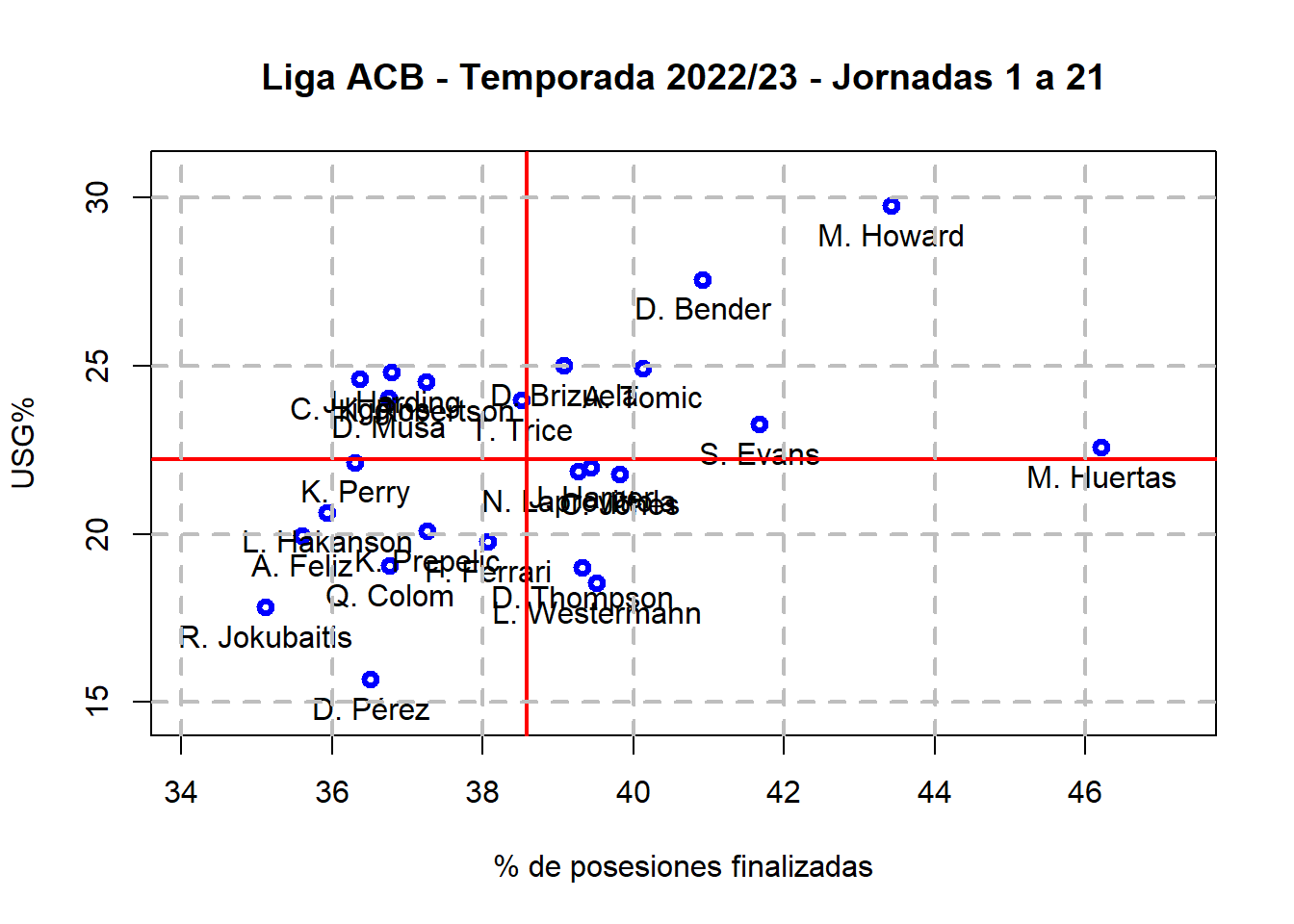
Representando %PosFJ frente USG% se observa que el máximo valor de USG% es menor que el mínimo valor de %PosFJ:
USG = datos_finales[,3]plot(PosFJ, USG, xlab="% de posesiones finalizadas", ylab="USG%", lwd=3, col="blue", main="Liga ACB - Temporada 2022/23 - Jornadas 1 a 21",xlim=c(min(PosFJ)-1, max(PosFJ)+1), ylim=c(min(USG)-1, max(USG)+1))text(PosFJ, USG, labels =rownames(datos_finales), col="black", pos=1)abline(v=mean(PosFJ), col="red", lwd=2)abline(h=mean(USG), col="red", lwd=2)abline(a=0, b=1, col="orange", lwd=2)grid(nx =NULL, ny =NULL, lty =2, col ="gray", lwd =2)
Es evidente que esto se debe a que en %PosFJ se tiene en cuenta a las faltas recibidas y las asistencias dadas, al contrario que en USG%, lo que podría hacer pensar que la primera es una medida más completa que la segunda.
Para finalizar, puesto que tenéis los datos disponibles y el código usado, podeís modificarlo para jugar con ellos modificando las condiciones de filtrado que yo he considerado. Por ejemplo, ¿quienes serán los jugadores que, finalizando más del 35% de las posesiones que se disputan mientras que están en pista, son los que menos finalizan con éxito?