De esta forma, por un lado se elimina la dependencia de la valoración ACB de los puntos anotados y, por otro, queda una media muy fácil de interpretar:
Si ValPtos > 0, entonces el resto de acciones positivas que hace un jugador (Rebotes + Asistencias + Recuperaciones + Faltas personales recibidas + Tapones realizados) superan a las negativas (Tiros fallados + Pérdidas + Tapones recibidos + Faltas cometidas).
Si ValPtos < 0, entonces el resto de acciones positivas que hace un jugador no superan a las negativas.
Por tanto, obviando el perfil anotador (el cual puede obtenerse de forma inmediata a partir de los puntos anotados), ValPtos podría usarse para detectar qué jugadores son más completos.
Para ilustrar los conceptos anteriores, voy a usar los datos de todos los jugadores de la Liga Endesa en su Temporada 2022-23 que han jugado en las 18 primeras jornadas:
library(readxl)datos <-read_excel("datos.xlsx", sheet ="datos")attach(datos)vistazo =head(datos)library(knitr)kable(vistazo, align ="c", caption ="Visualización de los datos que tenemos: unas pocas observaciones")
Visualización de los datos que tenemos: unas pocas observaciones
Apodo
Nombre
Equipo
Ptos
Val
MF2
M. Fjellerup
Girona
8
3
EV4
E. Vila
Girona
6
6
KT5
K. Taylor
Girona
22
26
PF7
P. Figueras
Girona
6
4
RP8
R. Prkacin
Girona
0
-1
QC10
Q. Colom
Girona
7
10
Como se observa, se tiene una leyenda a modo de apodo del jugador (iniciales más número), su nombre, equipo, puntos anotados y valoración.
En primer lugar, vamos a eliminar los datos pérdidos del conjunto de datos disponible y a confirmar la afirmación de que la valoración y la anotación están muy relacionadas:
sum(!is.na(Val) ==!is.na(Ptos)) # primero compruebo que los datos perdidos en 'Ptos' son los mismos que en 'Val'
[1] 3860
nrow(datos) # si la suma anterior coincide con el número de filas del conjunto de datos, la afirmación realizada es cierta
[1] 3860
datos_filtrados = datos[!is.na(Ptos),] # quitos los datos perdidos en Ptosdetach(datos)attach(datos_filtrados)cor.test(Ptos, Val)
Pearson's product-moment correlation
data: Ptos and Val
t = 96.42, df = 3608, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.8393914 0.8576472
sample estimates:
cor
0.848772
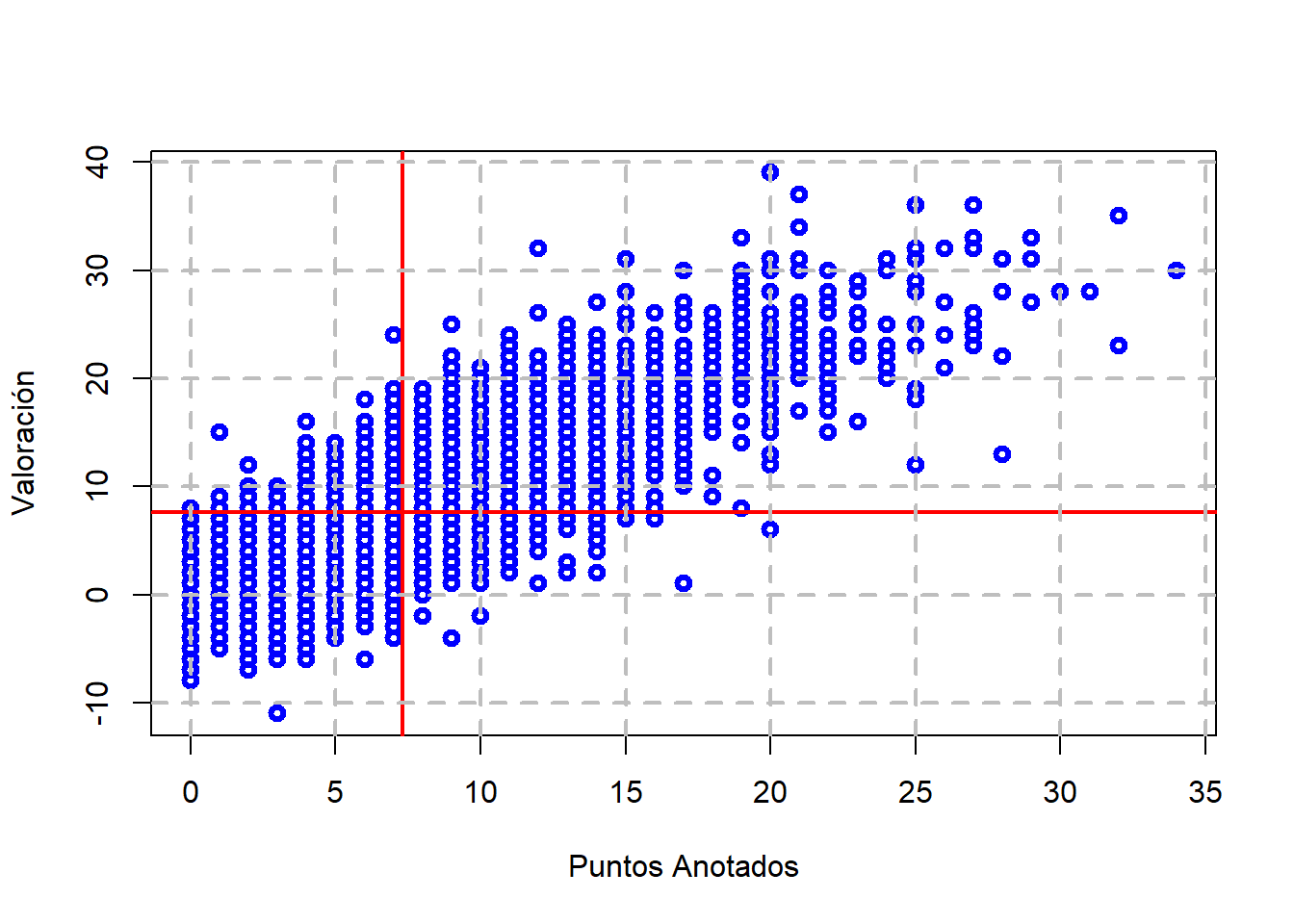
En este caso, se obtiene un coeficiente de correlación lineal simple igual a 0.848772 (significativamente distinto de cero). Por tanto, cuando una aumenta/disminuye la otra también lo hace tal y como se observa en la siguiente representación gráfica:
plot(Ptos, Val, xlab="Puntos Anotados", ylab="Valoración", col="blue", lwd=3)abline(h=mean(Val), col="red", lwd=2)abline(v=mean(Ptos), col="red", lwd=2)grid(nx =NULL, ny =NULL, lty =2, col ="gray", lwd =2)
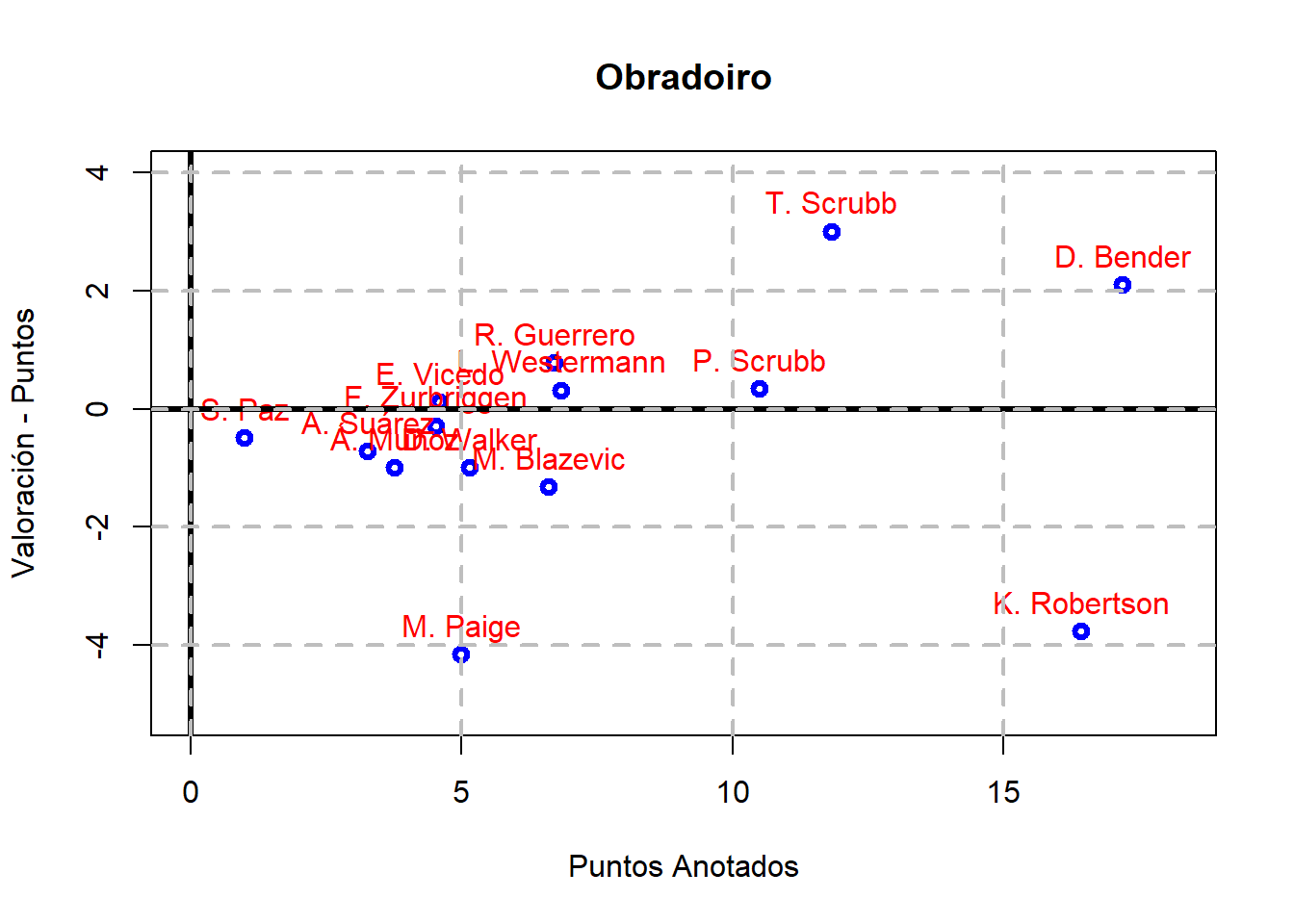
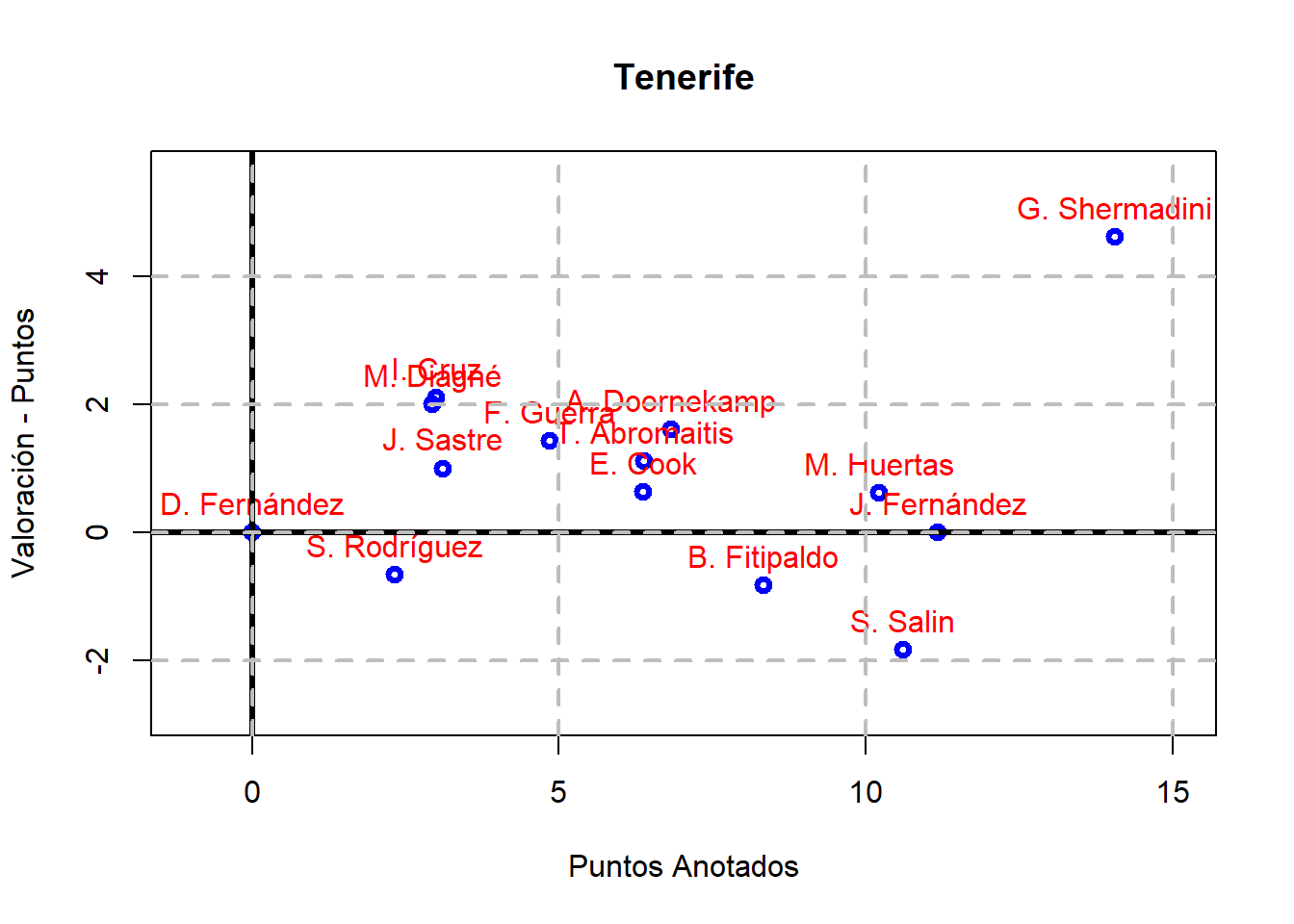
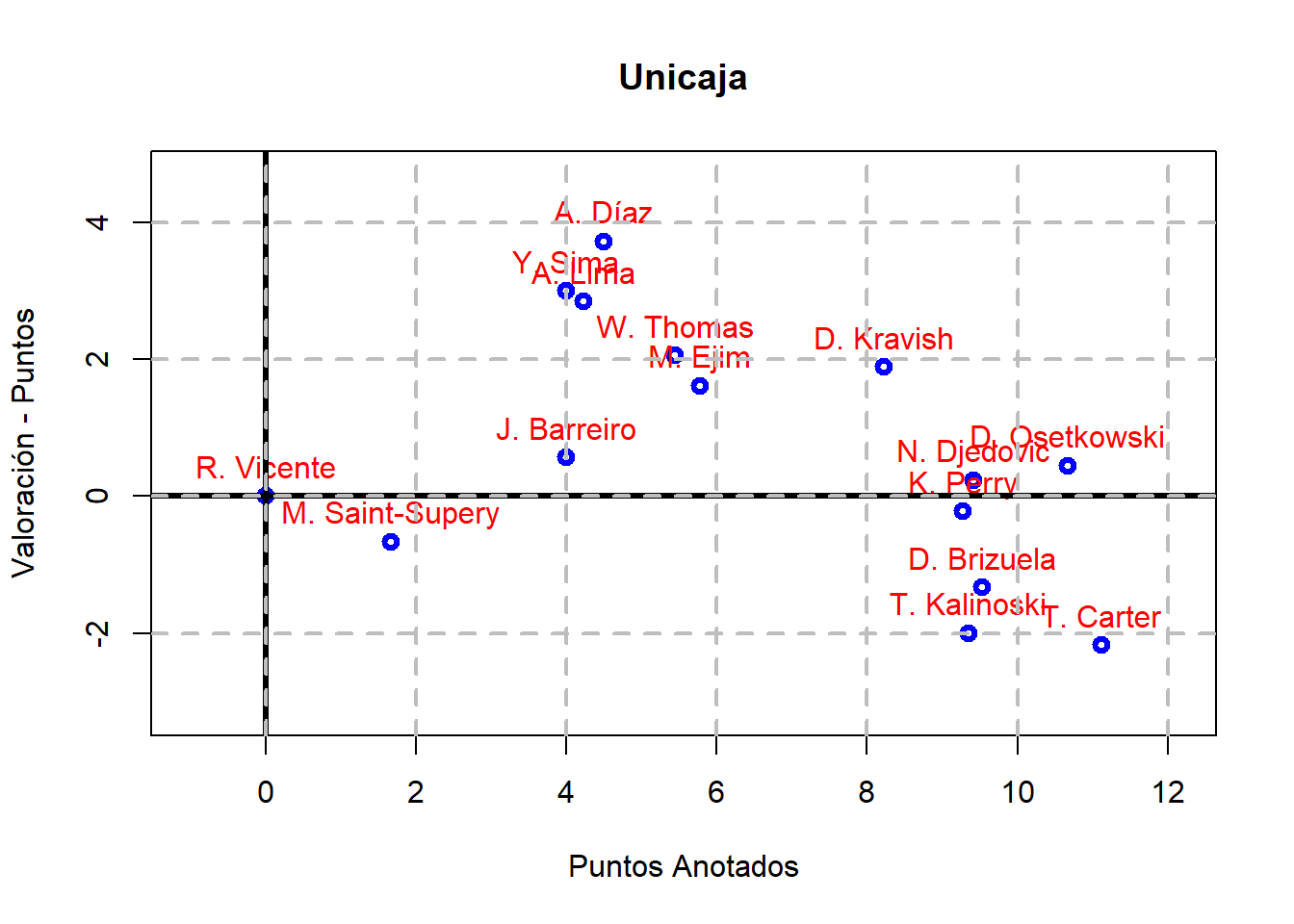
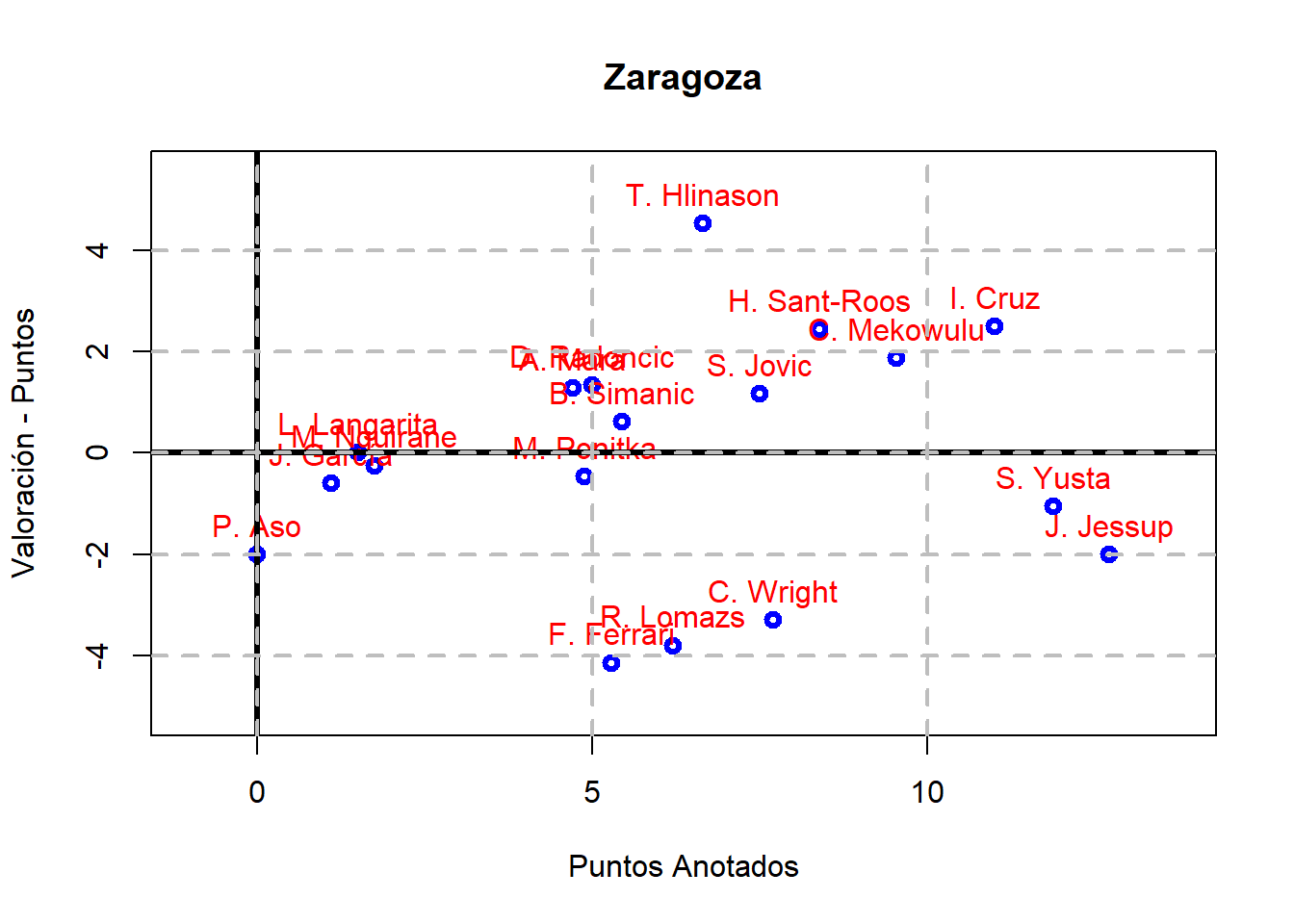
A continuación, vamos a considerar un equipo concreto (por ejemplo, el Covirán Granada) y vamos a calcular ValPtos para cada uno de sus jugadores y vamos a representar sus valores frente a los puntos anotados:
library(dplyr)jugadores =filter(datos_filtrados, Equipo =="Granada") ApodoBIS =as.matrix(jugadores[,1]) # si no pongo as.matrix no funciona tapplyNombreBIS =as.matrix(jugadores[,2])PtosBIS =as.matrix(jugadores[,4])ValBIS =as.matrix(jugadores[,5])ValPtosBIS = ValBIS - PtosBISPuntos =tapply(PtosBIS, NombreBIS, mean)ValPtos =tapply(ValPtosBIS, NombreBIS, mean)data.frame(Puntos, ValPtos)
Puntos ValPtos
Á. Corpas 0.000000 -1.00000000
A. Renfroe 10.444444 3.50000000
C. Díaz 6.000000 -1.61111111
C. Felicio 12.818182 0.09090909
D. Iriarte 1.200000 -1.40000000
D. Todorovic 5.333333 -3.66666667
J. Diaz 3.500000 -0.72222222
L. Costa 7.777778 -1.38888889
L. Maye 11.444444 -0.66666667
M. Caicedo 5.333333 -0.66666667
M. Moore 5.000000 -0.33333333
P. Ali 8.384615 -1.53846154
P. Niang 7.944444 5.11111111
P. Tomàs 4.444444 -0.27777778
R. Martín 0.000000 0.00000000
R. Vilà 2.400000 -1.60000000
T. Bropleh 12.222222 -3.38888889
Y. Ndoye 4.500000 -3.00000000
¿Qué se puede observar en esta representación gráfica?
Aquellos jugadores que están por encima del eje horizontal, se tiene que el número de acciones positivas superan a las negativas; mientras que las que están por debajo es al revés.
Así, se tiene que si bien Thomas Bropleh es el segundo máximo anotador por partido (sólo superado por Cristiano Felicio), es el segundo peor en cuanto a ValPtos (sólo superado por Dejan Todorovic). Es decir, una vez eliminada la anotación de Bropleh, sus acciones son fundamentalmente negativas.
Por otro lado, se tiene que Alex Renfroe es el cuarto máximo anotador del equipo y el segundo con mejor ValPtos (sólo superado por Petit Niang). Es decir, una vez eliminada su anotación, es un jugador en el que sus acciones positivas superan a las negativas.
Adviértase que sólo tres jugadores, Niang, Renfroe y Felicio (por los pelos), tienen un valor de ValPtos positivo.
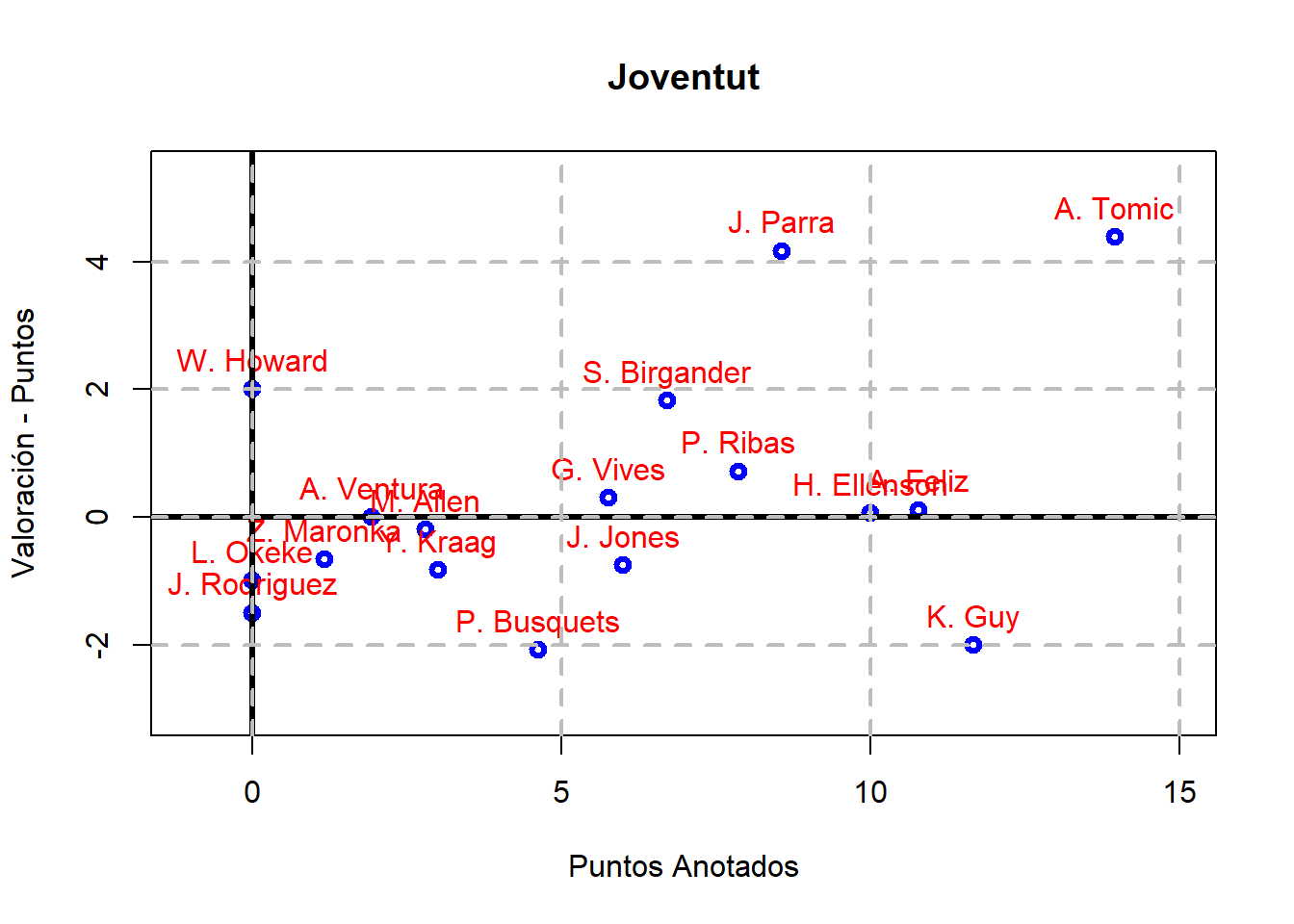
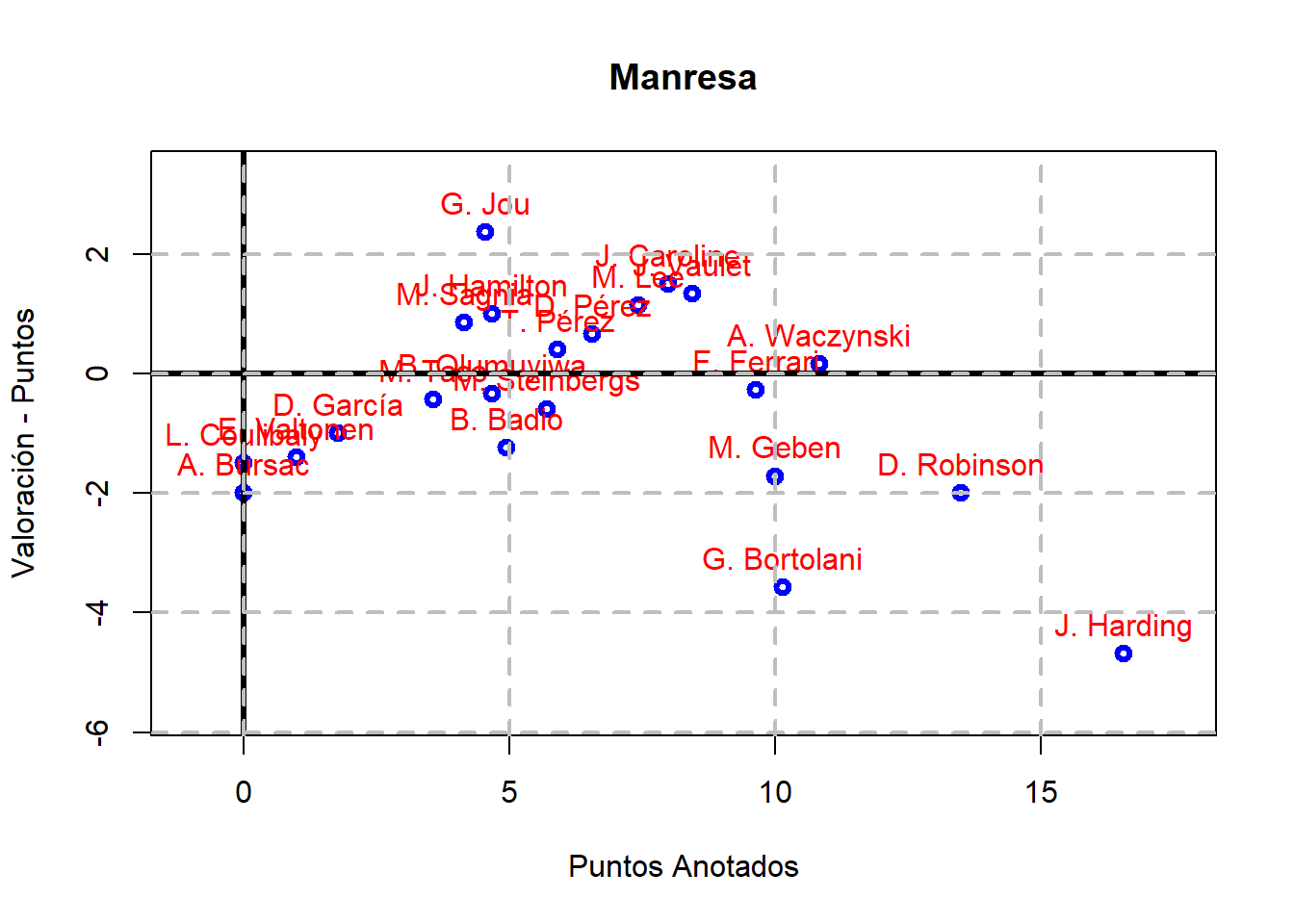
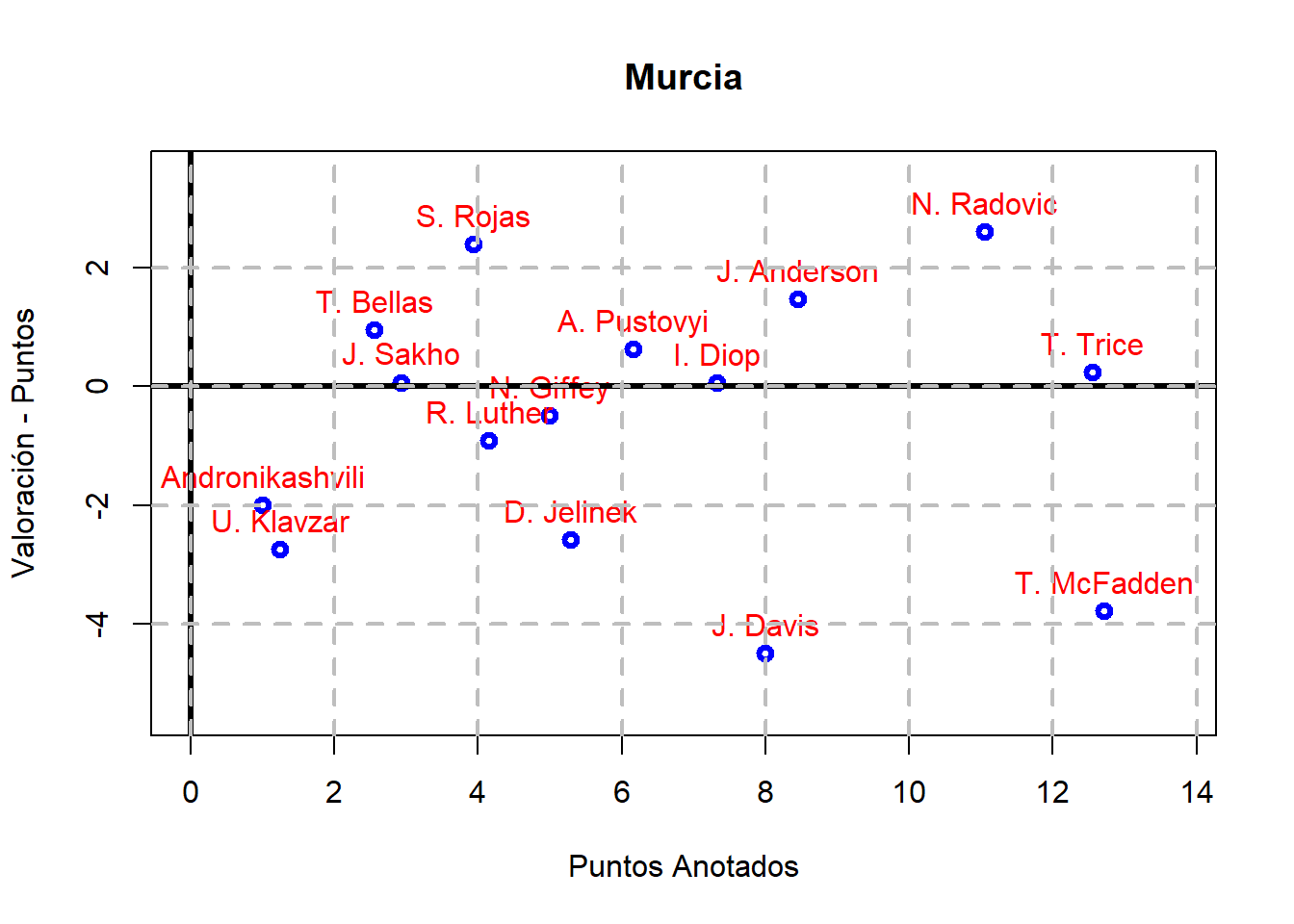
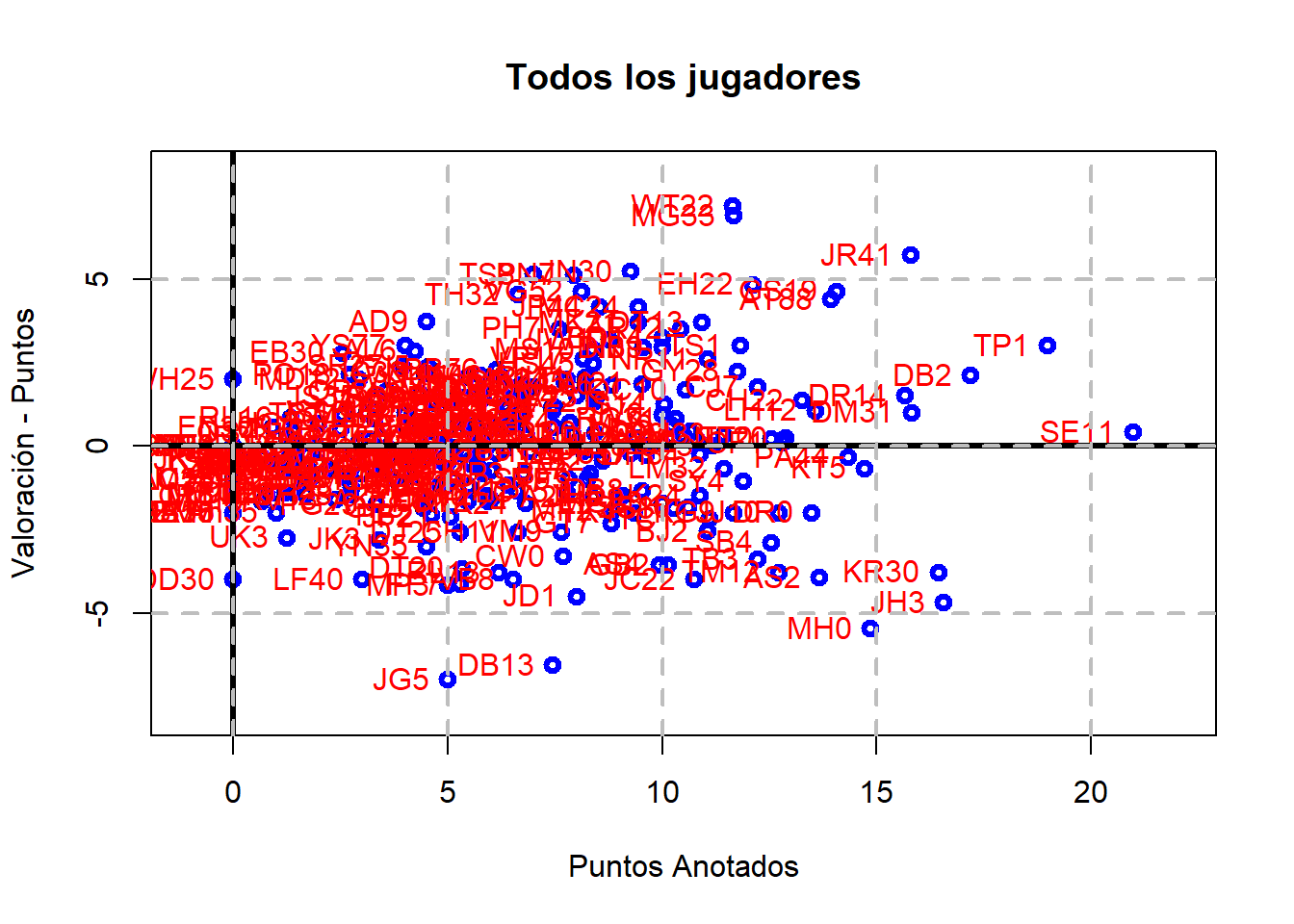
El código anterior se puede generalizar para obtener la misma gráfica de antes para los jugadores de cada uno de los equipos de la Liga ACB:
Son dos pivots, Walter Tavares y Marc Gasol, los que tienen un mayor ValPtos.
Centrándonos en dos jugadores de moda en la liga como son S. Evans (SE11, ex Betis) y M. Howard (MH0, Baskonia); se tiene que el primero tiene un ValPtos ligeramente positivo, mientras que el segundo es el tercer peor valor de ValPtos.
De cara a un futuro, se podría mejorar este análisis considerando que se ha jugado un número mínimo de partidos (así no se colaría por ejemplo T. Perez, TP1, como el segundo mejor anotador) o ponderando por el número de minutos jugados.